- 퍼셉트론(Perceptron)을 이해하고 python으로 구현할 수 있다.
- 신경망(Neural network)의 원리를 이해하고 기본적인 구조를 예를 들어 신경망을 설명할 수 있다.
- 신경망이 학습된다는 개념을 이해한다
퍼셉트론(Perceptron)이란?
뉴런들 사이에는 시냅스라는 연결이 뉴런마다 1000개에서 10000개까지 연결이 되어서 인터넷처럼 망으로
구성되어 뭔가 찾고 싶을 때, 구글링으로 빠르게 검색하여 결과를 얻는 것처럼,
뇌 속에서 소위 "생각"이라는 검색도구를 통해서 얻고자하는 정보를 빠르게 뇌속에서 찾을 수 있다.

가지(수상)돌기 : Dendrities
이런 개념을 본 딴 것이 퍼셉트론 == '생각'하는 것 같은 무언인가를 만드는 것
- 다수의 신호를 입력받아서 하나의 신호를 출력
단층 퍼셉트론(Single-Layer Perceptron)

* 단층 퍼셉트론은 값을 보내는 단계과 값을 받아서 출력하는 두 단계로만 이루어져 있다.
* 네트워크에서 한 개의 원을 뉴런(neuron) or 노드(node)라고 함
input 입력층 / output 출력층
w(가중치) = 각 입력신호가 결과에 영향력(중요도)을 조절하는 매개변수
b(편향) = 뉴런이 얼마나 쉽게 활성화(결과로 1을 출력)하느냐를 조정하는 매개변수
즉, 뉴런이 얼마나 쉽게 활성화되는지를 결정 = 임계치 Theta
각 신호에 가중치를 곱한 후, 다음 뉴런에 전달. 다음 뉴런에서는 이 신호들의 값을 더하여, 그 합이
0을 넘으면 1을 출력하고 or 넘지 않으면 0을 출력
* 편향의 입력신호는 항상 1이다.
* 활성화 함수란??
활성화 함수는 입력 신호의 총합을 출력 신호로 변환하는 함수이다.
단순한 논리게이트로 본 퍼셉트론

AND gate
* 입력신호가 모두 1 이어야 1을 출력
- 예) 밤에 라면을 먹고싶은데 먹어야 할까 말아야 할까를 고민하고 있습니다.
*두가지 조건 A, B가 있다고 했을 때
-- > 두가지 조건에 가중치를 부여하여함
- (1) 저녁을 안 먹었는가?
- (2) 11시 이전인가? 두 조건이 만족되었을 때 라면을 먹는다고 생각하는 최소한의 퍼셉으론을 구현한다고 할 때 이 게이트를 사용할 수 있습니다.

NAND gate = not AND gate
* 0은 1로, 1은 0으로 출력
/ AND gate의 결과 반대
def NAND(x1, x2):
w1, w2, theta = 0.5, 0.5, 0.7
tmp = x1*w1 + x2*w2
if tmp <= theta:
return 1 ## only change here
elif tmp > theta:
return 0 ## only change here
OR gate
* 입력 신호가 하나만 1이어도 1을 출력
def OR(x1, x2):
w1, w2, theta = 0.5, 0.5, 0.3 ## only change here
tmp = x1*w1 + x2*w2
if tmp <= theta:
return 0
elif tmp > theta:
return 1XOR gate == 단층 퍼셉트론의 한계 / 다층 퍼셉트론으로는 가능
배타적 논리합
입력값 두 개가 서로 다른 값을 갖고 있을때에만 출력값이 1이 되고,
입력값 두 개가 서로 같은 값을 가지면 출력값이 0이 되는 게이트
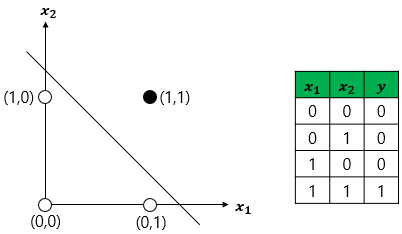

==>
AND, OR, NAND 직석으로 나누는 것이 가능
단층 퍼셉트론은 선형 영역에
대해서만 분리가 가능
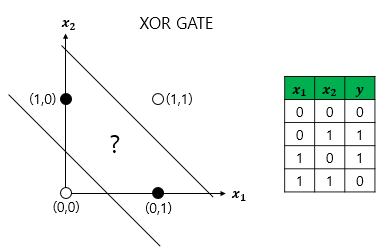
하얀색 원과 검은색 원을 직선 하나로 나누는 것은 불가능
즉, 단층 퍼셉트론으로는 XOR 게이트를 구현하는 것이 불가능
==>
XOR 게이트는 직선이 아닌 곡선.
비선형 영역으로 분리하면 구현이 가능
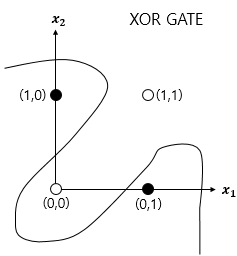
XOR 게이트는 기존의 AND, NAND, OR 게이트를 조합하면 만들 수 있다.
퍼셉트론 관점에서 보면, 층을 더 쌓으면 가능
but 층을 더 쌓는다고 해서 비선형이 되는 것은 아니다
Activation Function 함수 필요
밑에서 설명하겠다.
== 다층 퍼셉트론 ( 입력층, 은닉층, 출력층 ) == MLP
def XOR(x1, x2):
s1 = NAND(x1, x2)
s2 = OR(x1, x2)
y = AND(s1, s2)
return y
다층 퍼셉트론(MultiLayer Perceptron, MLP)
- 순방향 신경망 ( Feedforward Propagation ) as FP

입력층 (Input Layers)
- 입력층은 데이터셋으로부터 입력을 받습니다.
- 입력 변수의 수와 입력 노드의 수는 같습니다. ( Feature 수 )
- 보통 입력층은 어떤 계산도 수행하지 않고 그냥 값들을 전달하기만 하는 특징을 가지고 있습니다.
- 신경망의 층수(깊이, depth)를 셀 때 입력층은 포함하지 않습니다.
은닉층 (Hidden Layers)
- 계산이 일어나는 층이 둘 이상인 신경망을 다층(multilayer) 신경망 이라고 부릅니다.
- perceptron에서 이름을 빌려와서, multilayer perceptron (MLP)라고 부르기도 합니다.
- 계산이 없는 입력층과 마지막 출력층 사이에 있는 층들을 은닉층(Hidden Layers) 이라고 부릅니다.
- 은닉층에 있는 계산의 결과를 사용자가 볼 수 없기(hidden) 때문에 이런 이름이 붙었습니다.
출력층 (Output Layers)
- 신경만 가장 오른쪽, 마지막 층이 출력층 입니다.
- 출력층에는 대부분 활성함수(activation function)가 존재하는데 활성화함수는 풀고자 하는 문제에 따라 다른 종류를 사용합니다.
- 회귀 문제에서 예측할 목표 변수가 실수값인 경우 활성화함수가 필요하지 않으며 출력노드의 수는 출력변수의 갯수와 같습니다.
- 이진 분류(binary classification) 문제의 경우 시그모이드(sigmoid) 함수를 사용해서 출력을 확률 값으로 변환하여 클래스(Class or label)를 결정하도록 합니다.
- 다중클래스(multi-class)를 분류하는 경우 출력층 노드가 부류 수 만큼 존재하며 소프트맥스(softmax) 함수를 활성화 함수로 사용합니다.
- 이때, loss function은 label의 형태가 "원-핫인코딩"이냐 "int형"이냐에 따라 다르다
- "원-핫 인코딩", loss = categorical_crossentropy
- "int형", loss = sparse_categorical_crossentropy
# 이진분류
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
# 구하고자하는 타겟값이 onehot 형태일때
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
# 구하고자하는 타겟값이 정수 형태일때
target = df["label"].values
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])- 복잡한 딥러닝 방법론들에서는 은닉층에서도 활성함수를 사용하기 시작합니다.

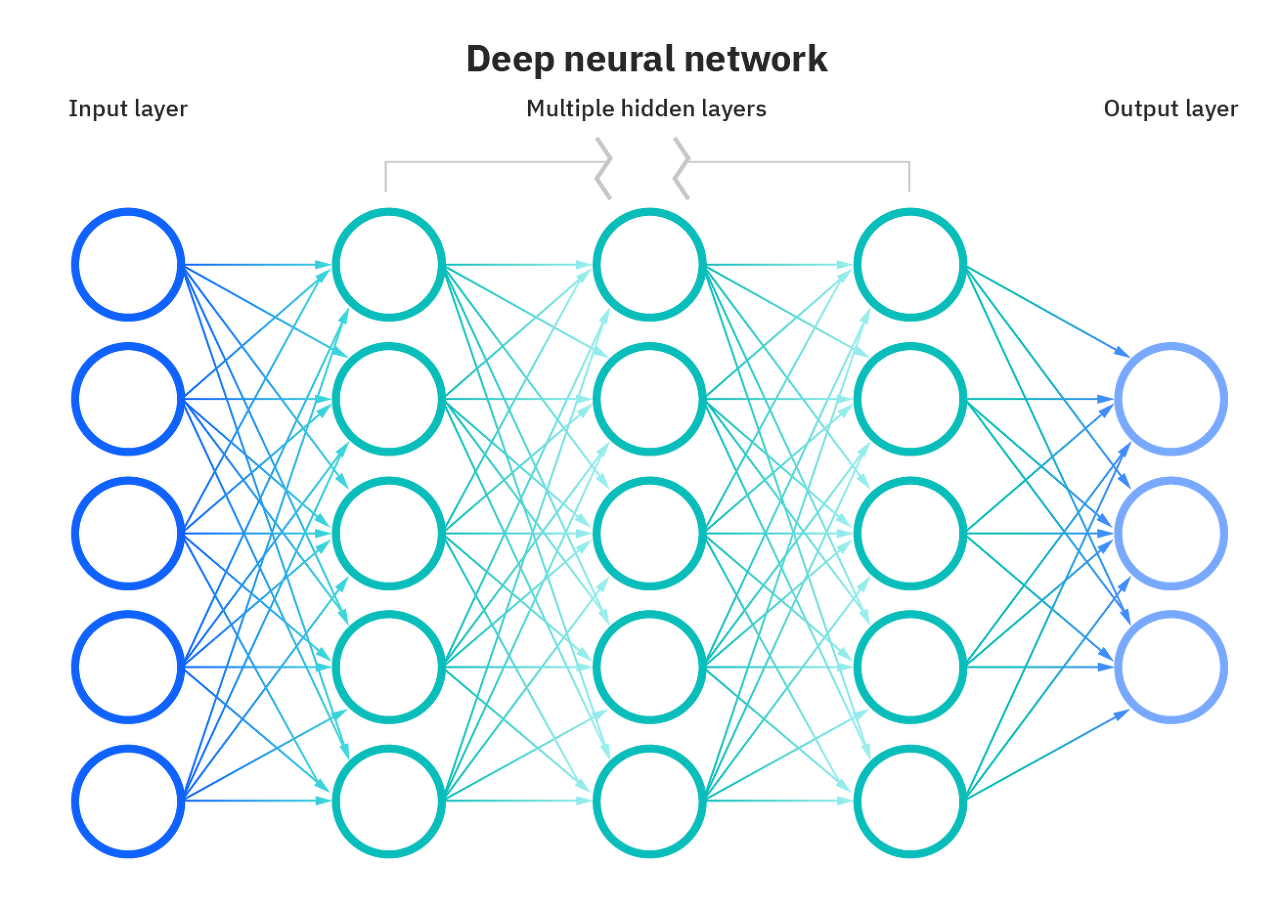
심층 신경망(Deep Neural Network, DNN)
XOR 문제보다 더욱 복잡한 문제를 해결하기 위해서 다층 퍼셉트론은 중간에 수많은 은닉층을 더 추가할 수 있다.
학습을 시키는 인공 신경망이 심층 신경망일 경우에는 이를 심층 신경망을 학습시킨다고 하여,
딥 러닝(Deep Learning)이라고 한다.
학습은? == >
가중치를 스스로 찾아내도록 자동화시키는 것
( 입력층과 출력층은 고정값이다 그러니 성능을 올릴 수 있는 것은 가중치와 편향을 학습시켜야된다)
==> 손실함수(loss function)와 최적화(optimizer)를 사용
왜 손실함수를 사용하는가?(=지표)
이 의문은 신경망 학습에서의 “ 미분 “ 의 역할에 주목한다면 해결 된다.
신경망 학습에서는 최적의 매개변수 ( 가중치와 편향 ) 를 탐색할 때 손실 함수의 값을 가능한 한 작게
하는 매개변수 값을 찾게 된다.
이때 매개변수의 미분 ( 기울기 ) 를 계산하고, 그 미분 값을 단서로 매개변수의 값을 서서히 갱신하는
과정을 반복한다.
가령 가상의 신경망이 있다고 가정하고, 그 신경망의 어느 한 가중치 매개변수에 주목한다고 하자.
이때 그 가중치 매개변수의 손실 함수의 미분이란, “ 가중치 매개변수의 값을 아주 조금 변화 시켰을 때,
손실 함수가 어떻게 변하는가? “ 이다. 만약 이 미분값이 음수라면 매개변수를 양의 방향으로 변화 시키고,
미분값이 양수라면 매개변수를 음의 방향으로 변화 시켜 손실함수의 값을 줄일 수 있다.
그러나 미분 값이 0이면 가중치 매개변수를 어느 쪽으로 움직여도 손실 함수의 값은 달라지지 않는다.
그 이후로 가중치 매개변수의 갱신은 멈추게 된다.
만약 정확도가 지표였다면 가중치 매개변수의 값을 조금 바꾼다고 해도
개선된다 하더라도 그 값은 32.0123%와 같은 연속적인 변화보다는 33%나 34% 처럼 불연속적인
띄엄띄엄한 값으로 변경되기 마련이다.
=정확도를 지표로 삼아서 안 되는 이유는 미분 값이 대부분의 장소에서 0이 되어 매개변수를
갱신할 수 없기 때문이다.
손실 함수를 지표로 삼았다면?손실 함수의 값은 0.92543…. 같은 수치로 나타난다. 그리고 매개변수의
값이 조금 변하면 그에 반응하여 손실 함수의 값도 0.93432…. 처럼 연속적으로 변화하는 것이다
신경망 학습은 데이터에서 필요한 특성들을 신경망이 알아서 조합하여 찾아낸다
즉, 우리는 최소한의 데이터에 대한 전처리는 해야 하지만 심화된 특성 공학(Feature Engineering)을
사용해 특성들을 찾아낼 필요는 없다
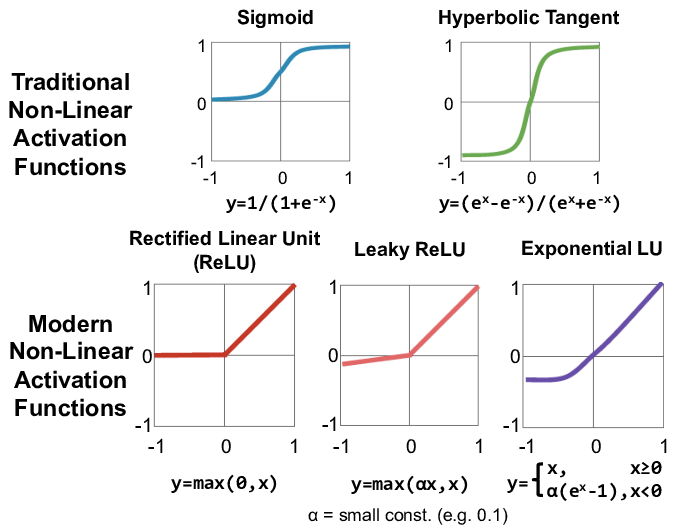
활성화 함수 ( Activtaion Function ) 이란 ? 비선형 함수
실제 뉴런세포에서 신호를 전달(activate or fire)할지 안 할지를 결정하는 기능을 말하는데
인공신경망에서 활성화 함수는 다음 층으로 신호를 얼마만큼 전달할지를 결정
간다하게 말해서 출력값을 활성화를 일으키게 할 것이냐를 결정하고, 그 값을 부여하는 함수
계단 함수(Step function)를 활성화 함수로 사용하지 않는 이유
만약 활성화 함수로 계단 함수를 사용하면 지금까지 설명한 것과 같은 이유로 신경망 학습이 잘 이뤄지지 않는다.
계단 함수의 미분은 대부분의 장소 ( 0 이외의 곳 ) 에서 0이다. 그 결과, 계단 함수를 이용하면 손실 함수를 지표로
삼는게 아무 의미가 없게 된다. 매개 변수의 작은 변화가 주는 파장을
계단 함수가 말살하여 손실 함수의 값에는 아무런 변화가 나타나지 않기 때문이다.
== 정확도가 아닌 손실함수로 지표를 삼는 이유와 들어 맞는다.
왜?
우선 인공 신경망은 입력에 대해서 순전파(forward propagation) 연산을 하고, 그리고 순전파 연산을
통해 나온 예측값과 실제값의 오차를 손실 함수(loss function)을 통해 계산하고,
그리고 이 손실(loss)을 미분을 통해서 기울기(gradient)를 구하고, 이를 통해 역전파(back propagation)를 수행
sigmoid
- 출력층 이진분류일 경우 사용
기울기가 완만해지는 구간( 1, 0 ) 이부분에서의 기울기는 0에 가깝다
역전파 과정에서 0에 가까운 아주 작은 기울기가 곱해지게되면 앞단에 기울기가 잘 전달 되지않는다.
==> 기울기 소실(Vanishing Gradient) 라고 한다. 가중치가 업데이트 되지 않는다.
==> so, 은닉층에서 사용되는것은 지양된다.
Hyperbolic Tangent
이 함수도 마찬가지로 기울기 소실이 발생하기 때문에 은닉층에서 사용은 지양된다
but 시그모이드 함수와는 달리 0을 중심으로 하고 있는데, 이때문에 시그모이드 함수와 비교하면
반환값의 변화폭이 더 크기 때문에 기울기 소실 증상이 적은편
== Sigmoid함수보다 많이 사용됨
ReLU Rectified Linear Unit
렐루 함수는 음수를 입력하면 0을 출력하고, 양수를 입력하면 입력값을 그대로 반환
렐루 함수는 특정 양수값에 수렴하지 않으므로 깊은 신경망에서 시그모이드 함수보다 훨씬 더 잘 작동
어떤 연산이 필요한 것이 아니라 단순 임계값이므로 연산 속도도 빠르다.
but 입력값이 음수면 기울기도 0이 된다.
Leaky ReLU == ReLU완화 버전
입력값이 음수일 경우에 0이 아니라 0.001과 같은 매우 작은 수를 반환하도록
softmax
- 출력층 다중분류일 경우 사용
왜 활성화 함수는 비선형 함수를 사용해야하는가?
단층 퍼셉트론으로 선형분류기라는 한계가 있었다. 이를 해결하기 위해 나온 개념이 hidden layer인데
무작정 층을 쌓는다고해서 선형분류기를 비선형분류기로 바꿀 수 있는 것은 아니다.
linear한 연산을 갖는 layer를 수십개 쌓아도 결국 이는 하나의 linear 연산으로 나타낼 수 있다.
가중치를 준 값의 합을 계산해보면 어떤 값이라도 나올 수 있다.
가중치를 준 값의 합을 0과 1사이의 숫자로 만들어 줘야한다.( 신경망을 통해 알아야할 것이 0과 1이라면 )
이때 사용하는 것이 활성화 함수

간단한 예)
활성화 함수는 f(x)=Wx라고 가정하고
여기다가 은닉층을 두 개 추가한다고하면 출력층을 포함해서 y(x)=f(f(f(x)))가 된다.
이를 식으로 표현하면 W×W×W×x입니다. 그런데 이는 잘 생각해보면 W의 세 제곱값을 k라고 정의해버리면
y(x)=kx와 같이 다시 표현이 가능
즉, 선형 함수로는 은닉층을 여러번 추가하더라도 1회 추가한 것과 차이를 줄 수 없다
결과적으로 은닉층이 없는 네트워크로도 표현이 충분히 가능하다
이렇게 활성화 함수를 이용하여 비선형 시스템인 MLP를 이용하여 XOR는 해결될 수 있지만,
MLP의 파라미터 개수가 점점 많아지면서 각각의 weight와 bias를 학습시키는 것이 매우 어려워진다.
이를 해결한 알고리즘이 역전파(Back Propagation)이다.
'Deep Learning, DL > Neural Networks' 카테고리의 다른 글
| Neural Network Hyperparameter (0) | 2021.08.16 |
|---|---|
| 기울기 소실 Vanishing, 발산 Exploding (0) | 2021.08.15 |
| Weight Regularization 과적합 방지 (0) | 2021.08.15 |
| sigmoid 미분 (0) | 2021.08.14 |
| 역전파( Back Propagation ), 최적화(Optimizer) (0) | 2021.08.14 |




댓글