미분 = 함수를 작게 나눈다. ==> 특정부분에서의 순간 변화율을 찾기 위해서
변화율이 한없이 0에 가까워 질때의 기울기를 계산하는것 ==> y = b + ax
# 랜덤하게 평균0, 표준편차1의 가우시안 표준정규분포 난수 x, y를 50개씩 뽑습니다
np.random.seed(42) # 동일한 결과를 보기 위해 시드를 고정합니다. https://numpy.org/doc/stable/reference/random/generated/numpy.random.seed.html
x = np.random.randn(50)
y = np.random.randn(50)
#seaborn 을 통해서 산점도를 확인할 수 있음
sns.regplot(x, y)
plt.show()

y'(오차함수) = b + ax ( 알파는 y절편, 베타는 기울기(slpoe)
x를 넣었을때 y 값을 예측
a, b를 찾는 것이 머신러닝의 목표 / 0에 가까운 값을 찾는것
결국은 오차함수를 최소화 하는것
미분을 통해서 오차함수의 도함수 (f'(x)) = 0
0에 근사한 값을 보통 1e-5로 잡는다 = numerical method

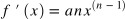
========>> f(x)의 도함수
from scipy.misc import derivative 를 활용 할수 있음(함수를 미분 =도함수를 계산해줌
==> 소수점이 무한대로 가기 때문에 Rounding Error로 값이 미묘하게 다름
##derivative(f, df_iris['x'], dx= 1e-7) == > x칼럼에 있는 값을 사용하여 미분하겠다.!
**파이썬에선 자연상수e는 나오지 않기때문에
np.e or
import math 를 쓰게 되면 math.e 사용하면된다.
np.exp(x) == > 자연상수 e의 제곱근
편미분 (partial derivation)
*편미분 = x축과 y축의 변화율
우선 1개의 파라미터에 대해서만 미분을 하자 라는 목적으로 다른 변수들을 상수 취급 하는 방법을 말합니다.
===> y는 상수 취급 x를 기준으로 미분// 미분하게되면 y는 다 없어진다고 보면됨
예시) f = ma // 기준에 따라 확인 해 볼 수 있음
현재 차의 무게는 그대로 두고 가속도에 변화를 주는 경우 충격은 어떻게 변화하는가? 충격 / 가속도
현재 가속도는 그대로 두고 차의 무게에 변화를 주는 경우 충격은 어떻게 변화하는가? 충격 / 무게
연쇄 법칙 Double chain rule
= 외부함수를 먼저 미분을 하고나서 내부함수를 2차로 미분하는 것
*경사하강법(Gradient Descent) == 최적화 알고리즘 GD==> 파라미터의 갯수가 수없이 많을 때는 min/max 만이 존재하지 않은 상황에
임의의 a, b를 선택한 후 (random initialization)에 기울기 (gradient)를 계산해서 기울기 값이 낮아지는 방향으로 진행합니다. 기울기는 항상 손실 함수 값이 가장 크게 증가하는 방향으로 진행합니다. 그렇기 때문에 경사하강법 알고리즘은 기울기의 반대 방향으로 이동합니다.
- 기울기 = 어떤 직선이 수평으로 증가한 크기만큼 수직으로 얼마나 증가했는지를 나타내는 값이다. <=> 경사하강법
손실 함수란? 최적화를 위해 사용하는 함수라고 보시면됩니다
epoch 반복 횟수
학습률이 너무 낮게 되면 알고리즘이 수렴하기위해서 반복을 많이 하게됨
학습률이 너무 크면 극소값을 지나쳐 버려서 수렴을 못하고 반복을 많이 하게됨
학습률(learning rate, ?) 파이썬에선 lr = 표현//
'Data Analysis, DA > Data Process & EDA' 카테고리의 다른 글
| n113 Data Manipulation(merge, melt, concat) (0) | 2021.05.10 |
|---|---|
| N111a EDA(Exploratory Data Analysis) (0) | 2021.05.09 |
| N112a Feature Engineering / iloc (0) | 2021.05.09 |

댓글