반응형
호모그래피(Homography)란?
• 두 평면 사이의 투시 변환(Perspective transform)
• 8DOF : 최소 4개의 대응점 좌표가 필요
왜 호모그래피?
Perspective Transform(투시 변환): 4개의 쌍(8 DOF)만 있으면 되는데
내가 줄수 있는 수식은 8개(DOF) 보다 더 많을 때
==> 연결관계가 4개 이상 나오고 그 중에서 잘못된 매칭이 있을 수 있다라는 가정
==> 이런 조건에서 Perspective 계산 어떻게? == 호모그래피 사용

src1 = cv2.imread('ch09\\images\\box.png', cv2.IMREAD_GRAYSCALE)
src2 = cv2.imread('ch09\\images\\box_in_scene.png', cv2.IMREAD_GRAYSCALE)
if src1 is None or src2 is None:
print('Image load failed!')
sys.exit()
feature = cv2.KAZE_create()
#feature = cv2.AKAZE_create()
#feature = cv2.ORB_create()
kp1, desc1 = feature.detectAndCompute(src1, None)
kp2, desc2 = feature.detectAndCompute(src2, None)
matcher = cv2.BFMatcher_create()
#matcher = cv2.BFMatcher_create(cv2.NORM_HAMMING)
matches = matcher.match(desc1, desc2)
matches = sorted(matches, key=lambda x: x.distance)
good_matches = matches[:60]
# 호모그래피 계산
# good_matches = 80개의 특징점
# m = DMathch의 tpye
# DMathch라는 클래스에는 queryIdx와 trainIdx가 멤버가 있다.
# pt= kp1[m.queryIdx]의 좌표 (80,2) float64
pts1 = np.array([kp1[m.queryIdx].pt for m in good_matches]
).reshape(-1,1,2).astype(np.float32)
pts2 = np.array([kp2[m.trainIdx].pt for m in good_matches]
).reshape(-1,1,2).astype(np.float32)
# H = perspective transform 정보를 가지고 있는 행렬
H, M = cv2.findHomography(pts1, pts2, cv2.RANSAC)
'''
cv2.findHomography(srcPoints, dstPoints, method=None,
ransacReprojThreshold=None, mask=None, maxIters=None,
confidence=None) -> retval, mask
retval: 호모그래피 행렬. numpy.ndarray. shape=(3, 3). dtype=numpy.float32.
mask: 출력 마스크 행렬. RANSAC, RHO 방법 사용 시 Inlier로 사용된
점들을 1로 표시한 행렬. numpy.ndarray. shape=(N, 1), dtype=uint8
inliers = 두 특징점이 매칭된 것은 1, 아닌 것은 0으로
'''
# 호모그래피를 이용하여 기준 영상 영역 표시
# 두 이미지가 가로로 합쳐져서 나옴
# flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS(매칭되는 점이 아는 건 버림)
dst = cv2.drawMatches(src1, kp1, src2, kp2, good_matches, None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
dst2 = cv2.drawMatches(src1, kp1, src2, kp2, good_matches, None)
# Perspective
(h,w) = src1.shape[:2]
corners1 = np.array([[0,0], [0, h-1], [w-1, h-1], [w-1,0]] #(4,2)
).reshape(-1,1,2).astype(np.float32) # (4,1,2)
# 점들을(H라는 행렬) 어디로 좌표가 이동하는지
# H.shape = (4, 1, 2)
perspective = cv2.perspectiveTransform(corners1, H)
# 합쳐져서 나오니까 이미지1의 가로 길이만큼 shift시킨다
perspective = perspective + np.float32([w,0])
cv2.polylines(dst, [np.int32(perspective)], True, (0,255,0), 2, cv2.LINE_AA)
cv2.imshow('src1', src1)
cv2.imshow('src2', src2)
cv2.imshow('dst', dst)
cv2.imshow('dst2', dst2)
cv2.waitKey()
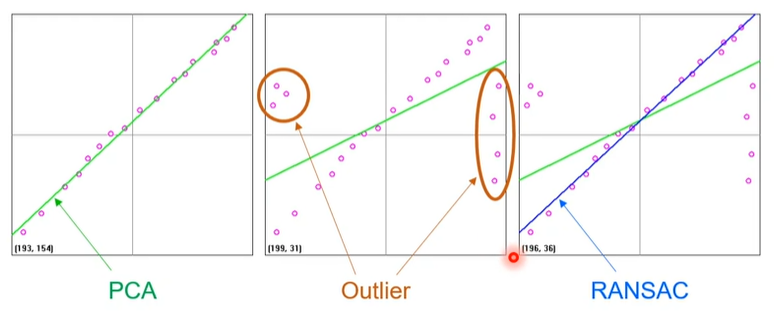
RANSAC(RAndom SAmple Cousensus)이란?
- 이상치(Outlier)가 많은 원본 데이터로부터 모델 파라미터를 예측하는 방법
- 임의의 점 2개(분포에서) 선택하고 직선을 긋고, 선 양옆으로 Margine을 긋고
그 안에 포함된 분포의 개수 파악 == 반복
==> 가장 많이 counting된 값 찾음

*Flow*
1. 기술자, 특징벡터(KAZE, AKAZE...) == Class 선언
2. 특징점 검출 create, detect, compute ( Keypoint, Descriptor )
3. 매칭(BFmatch) == Class 선언
4. good matching - 잘 매칭된 것만 선별
5. Homography 사용(RANSAC) == Outlier가 많아도 매칭을 잘 할 수 있다.
== 장점: 그림의 형태가 가려져 있어도 어느정도 보여줌
** 크기와 회전이 무관하게 매칭하는 알고리즘이 특징점과 매칭이다.
반응형
'OpenCV > OpenCV-Chapter' 카테고리의 다른 글
| CH10 OpenCV-Python 객체 추적(배경차분) (2) | 2021.12.25 |
|---|---|
| CH09 OpenCV-Python 스티칭 Stitching(PANORAMA) (0) | 2021.12.25 |
| CH09 OpenCV-Python 특징점 매칭(feature point matching) (0) | 2021.12.25 |
| CH09 OpenCV-Python SIFT, KAZE, AKAZE, ORB.. (0) | 2021.12.25 |
| CH09 OpenCV-Python 특징점 검출(Corner) (0) | 2021.12.25 |




댓글