*중심극한정리 ( Central Limit Theorem, CLT )
- sample 데이터의 수가 많아질 수록, sample의 평균은 정규분포에 근사한 형태로 나타난다.
*큰 수의 법칙 ( Law of large numbers )
sample 데이터의 수가 커질 수록, sample의 통계치는 점점 모집단의 모수와 같아진다.
**표본의 크기 >= 30 가 되야 크다고 본다(작으면 비모수적 방법 적용)
'큰수의 법칙'은 표본 크기가 무한히 커짐에 따라
표본평균이 모평균으로 "확률수렴"을 한다는 개념이고,
'중심극한정리'는 표본 크기가 무한히 커짐에 따라
표준화한 표본평균의 분포가 표준정규분포로 "분포수렴"하는 개념
정규분포(Normal Distribution)는 특정 값의 출현 비율을 그렸을 때, 중심(평균값)을 기준으로 좌우 대칭 형태로 나타나며, 이것은 종의 모양으로 나타난다.
표준 정규분포(Standard normal distribution)는 평균이 0이고 표준 편차가 1인 분포를 얘기하며, z-분포라고 부르기도 한다.
***중요***
- 독립성 : 두 그룹의 연결되이 있는 쌍인지( = 비교대상이 같은지)
- 등분산성 : 두 그룹이 어느정도 유사한 수준의 분산 값을 가지는지
- 정규성 : 정규분포 양상인지
- 만약 아니라면 scipy normal test 시행 == 비모수적 방법 Non parametric methods
- ====>>>모집단이 특정확률분포를 따르지 않음을 전제하는 방식
* 모수적
- 중심극한정리에 의해 본래의 분포에 상관없이 무작위로 복원추출된 연속형 자료의 평균의 분포는 정규분포를 띤다.
- 비교하고자 하는 두 집단이 모두 정규분포를 띤다면, 그 두 집단은 평균을 비교함으로써 차이를 밝힐 수 있다.
= 정규성을 갖는다는 모수적 특성을 이용하는 통계적 방법을 모수적 방법(parametric methods)이라고 한다.
= 중심극한정리에 의해 정규분포를 가정할 수 있는 최소한의 표본(= 군 당 30명 이상 or 10<=n<30의 경우, 정규성 검정에서 정규분포로 간주되는 연속형 자료의 경우)
만약, 10명 미만인 소규모 실혐 or 정규성 검정에서 정규분포를 따르지 않을경우 다음 모수적 방법을 사용하게 된다
* 비모수적
- 자료를 크기 순으로 배열하여 순위를 매긴 다음 순위의 합을 통해 차이를 비교하는 순위합검정을 적용
= 모수의 특성을 이용하지 않는다고 하여 비모수적 방법(Non parametric methods)이라고 한다.
표본의 통계량(평균, 표준편차 등)을 통해 모집단의 모수(모평균, 모표준편차 등)를 추정하는 방법을 통계적 추론이라고 한다.
모집단이 어떤 분포를 따른다는 가정 하에 통계적 추론을 하는 방법을 모수적 방법이라 하는데, 표본의 수가 30개 이상일 때 중심극한 정리에 의해 정규분포를 따르므로 모수적 방법론을 사용한다.
반대로, 모집단의 분포를 가정하지 않는 비모수적 방법은, 표본의 수가 30개 미만이거나 정규성 검정에서 정규 분포를 따르지 않는다고 증명되는 경우 비모수적 방법론(부호 검정 (sign test), 윌콕슨 순위합 검정 (Wilcoxon rank-sum test), 크루스칼-왈리스 검정 (Kruskal-Wallis test), 맨-위트니 검정 (Mann-Whitney U test) 등)을 사용한다.
표본 크기가 작을 때(n<30)는 어떻게 해야 하죠? 정규성 검정은 꼭? 이걸 모르면 궁금증의 지옥행
잠시 짚고 넘어가야 하는 이야기. 통계분석을 보다 보면 표본크기가 작을 때는 어떻게 해야 할지 막막해질 때가 있습니다. 통계란 무릇 표본으로 모집단을 예측하는 것이니 적당한 표본크기가
recipesds.tistory.com
<비모수적 방법>
- 분포 가정 없음: 비모수적 방법은 모집단의 분포에 대한 가정을 하지 않습니다. 따라서, 비모수적 방법은 데이터의 분포가 어떻게 되는지에 대한 가정 없이도 사용할 수 있습니다. 이는 실제 데이터에 더 적합한 방법을 제공할 수 있습니다.
- 순위 기반 분석: 대부분의 비모수적 방법은 데이터의 순위에 기반하여 분석을 수행합니다. 데이터의 순위를 사용함으로써, 비모수적 방법은 데이터의 분포를 고려하지 않고도 통계적 추론을 할 수 있습니다.
- 중앙값 기반: 비모수적 방법은 대부분 중앙값을 중심으로 분석을 수행합니다. 중앙값은 데이터의 중심 경향성을 나타내는데, 이는 평균값을 사용하는 모수적 방법과는 차이가 있습니다.
np.random.normal(50, 10, 1000) == 평균 50, 편차 10, 개수 1000
-변수.var == Variance
for i in np.range(start= , stop=, step= )
df.sample(개수, random_state = random.seed)와 같음
loc = 평균(기대값) / scale = 분산
*랜덤 표본 생성(random variable sampling)
rvs(df, loc=0, scale=1, size=1, random_state=None)
====> Random variates.
*분산
var(df, loc=0, scale=1)
====> Variance of the distribution.
*표준 편차
std(df, loc=0, scale=1)
=====> Standard deviation of the distribution.
*표준오차
std / sqrt(n)
==> math.sqrt(n) or n**0.5
stderr = stats.sem(data)예측 하는 "구간"이 넓어질 수록 맞을 확률(신뢰도)은 올라감.
but 값을 추정할 때는 (정확도를 생각할때는) 좁은구간이 좋음
*신뢰도
추정이란?
표본의 정보를 활용하여 모집단의 특징을 추측하는 것을 추정(= estimated)
 를 estimated mean.
를 estimated mean. 를 error라 부릅니다.
를 error라 부릅니다.
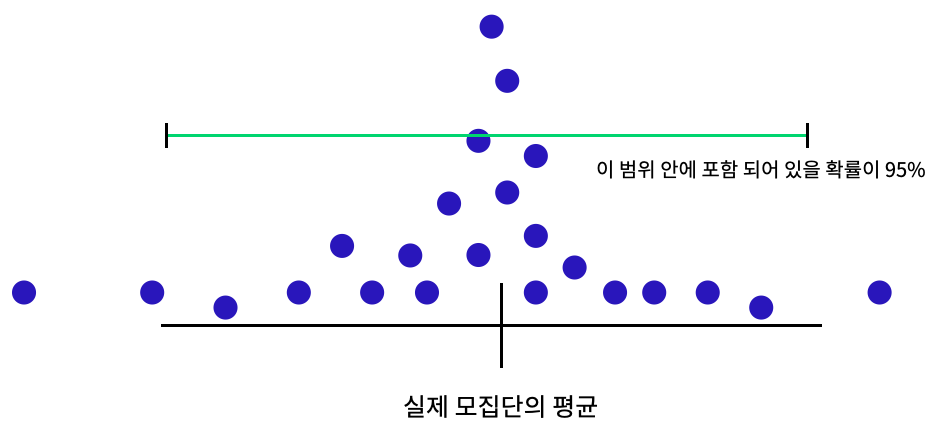
*신뢰구간의 변화
신뢰구간(Confidence Interval)
- 모집단의 모수(parameter)가 위치해 있을 것으로 신뢰할 수 있는 구간이다. 모수가 어느 범위 안에 있는지를 확률적으로 보여주는 방법이라고 할 수 있다. 신뢰구간을 구하는 이유는 모수의 신뢰성을 가늠하기 위함이다.
1. 신뢰도 95% / 99% - 신뢰도가 클수록 오차가 생길 가능성은 낮지만/ 추정가치가 없음
- 해석: 똑같은 방법으로 100번 표본을 추출했을 때, 함께 계산되는 100개의 신뢰구간 중 모평균을 포함한 신뢰구간들의 숫자가 95개정도 된다.(= 모평균을 포함할 확률이 95%)
2. 표본의 개수,크기 - 개수,크기가 클수록 신뢰구간은 짧아짐 ==> 표본이 크면 표본과의 오차가 적어짐
==> 즉, 분모에 있는 표본의 크기가 커지면 표본평균의 오차가 작아짐 = 모집단에 가까워짐
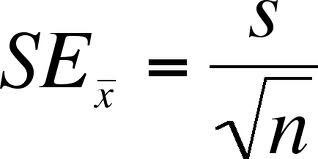
3. 표본 표준편차 - 분산이 클수록 신뢰구간 길어짐
<오차 VS 편차>
- 집단의 차이
- 편차 = 변량들이 평균에서 얼마나 떨어져있는지
표준편차 - 모집단이건 표본 집단이건 그 안의 숫자들의 편차(= 특정한 표본집단 내의 편차)
=> 자료전체의 편차가 어느정도인지 표준적인 값
표준오차 - 여러개 뽑히는 표본 평균들의 편차(= 표본집단들 (평균)간의 편차)
=> 표본의 참값인 모평균에서 얼마나 떨어져 있는지
#직접 계산시!
from scipy import stats
def confidence_interval(data, confidence = 0.95): #0.95 신뢰도를 정해놓고
data = np.array(data)
mean = np.mean(data)
n = len(data)
stderr = stats.sem(data)
interval = stderr * stats.t.ppf( (1 + confidence) / 2 , n - 1) # ppf : inverse of cdf
return (mean, mean - interval, mean + interval)
print(confidence_interval(s1['오존(ppm)']))
print(confidence_interval(s2['오존(ppm)']))#t.interval(신뢰도, 자유도, loc=평균, scale= 분산==>표준오차)
return (평균, 하한, 상한구간)으로 이루어진 tuple
dof = n -1
ddof = default 값이 1 (delta degree of freedom)
# 표본의 표준편차
sample_str1 = np.std(s1['오존(ppm)'], ddof = 1) # ddof = N - ddof
# 표준오차
std_err1 = sample_str1 / n1**0.5 or math.squt(n1)
*포이송분포(possion) = 특정사건이 발생할 가능성이 낮은 것을 나타나는 확률분포
*이항분포(binominal) = 연속적인 베르누이 시행을 거쳐 나타나는 확률 분포==> 의사결정을 할 것인가 / 안 할것인가.. #아직 모르겟음
*그래프
plt.figure(figsize=(12, 3)) 그래프 크기
plt.bar(x축, y축,
-yerr = 오차막대기, capsize= 굵기?
-width= 숫자가 커지면 비교하는 구간이(막대그래프 사이공간이 넓어짐)
-align= 정렬
-color= 두개를 비교할때는 ['color', 'color']인덱스로 묶어
-axhline(변수, 좌측길이, 우측길이, linewidth=, color=) // 매개변수 ls= (line style)
==> 변수의 최대값에 막대기 생성
'Data Analysis, DA > statistics' 카테고리의 다른 글
| N124 'Bayes Theorem' (0) | 2021.05.18 |
|---|---|
| N122 T-test++(카이제곱) (0) | 2021.05.15 |
| N121 기술통계치 / 가설검정 Hypothesis (0) | 2021.05.15 |



댓글