반복되는 챗봇 질문, 직접 만들면 안 될까?
요즘 사이트들을 보면 우측 하단에 챗봇 아이콘이 떠 있는 경우가 많다. 클릭하면 슬슬 등장하는 "무엇을 도와드릴까요?" 같은 인삿말. 그런데 이런 챗봇, 항상 아쉽다. 질문을 해보면 엉뚱한 답을 하거나, 특정 문서 기준으로 명확히 답해주지 못한다.
그래서 문득 생각했다.
내가 만든 PDF 문서를 기반으로 정확히 답해주는 AI 챗봇을 직접 만들 수는 없을까?
⚽ 내 문서 기반의 맞춤형 Q&A 챗봇 만들기
일반적인 GPT는 학습된 지식만을 기반으로 답변한다. 그러나 내 문서에 들어있는 고유한 내용을 정확히 반영하긴 어렵다. 이를 보완하는 방식이 바로 RAG (Retrieval-Augmented Generation) 이다.
🧩 왜 RAG 기반 챗봇이 필요한가?
LLM(예: GPT)의 한계
- 학습된 정보만 대답함 → 최신 정보엔 취약
- 법률, 의료, 회계 등 특정 도메인에 부정확
- 실제 문서 기반의 정확한 답변이 필요함
RAG의 역할
- 질문 시, 벡터 DB(Vector Store)에서 관련 문서를 검색
- 문서 내용을 기반으로 LLM이 응답 생성
- 대표적인 구성 요소: 벡터화(임베딩), 검색, 응답
https://cord-ai.tistory.com/189
AI의 똑똑함을 완성하는 두 축 - MCP와 RAG란?
1. 한눈에 이해하는 차이점 MCP (Model Context Protocol)RAG (Retrieval-Augmented Generation)설명사용자 정보와 맥락을 기억하고 반영하는 기술외부 문서나 데이터베이스에서 정보를 검색해 답변 생성초점“누
cord-ai.tistory.com
이번 프로젝트에서는 다음과 같은 목표를 설정했다.
- PDF 파일을 벡터화해서 저장
- ❗ 여기서 PDF 파일은 내가 개인적으로 만든 데이터를 사용했다.(실제 Data하고 다른 PDF)
- 질문이 들어오면 해당 문서에서 관련 내용을 찾아서 응답
- 대화 흐름을 기억하고 이어서 대답할 수 있게 메모리 기능도 탑재
환경 정보
- 플랫폼: n8n (Self-hosted)
- DB/Vector Store: Supabase
- LLM 모델: OpenAI GPT(+ Embedding )
- 기반 기술: RAG 구조, PDF → Embedding → 벡터DB 저장
- 데이터: 직접 제작한 .pdf 문서
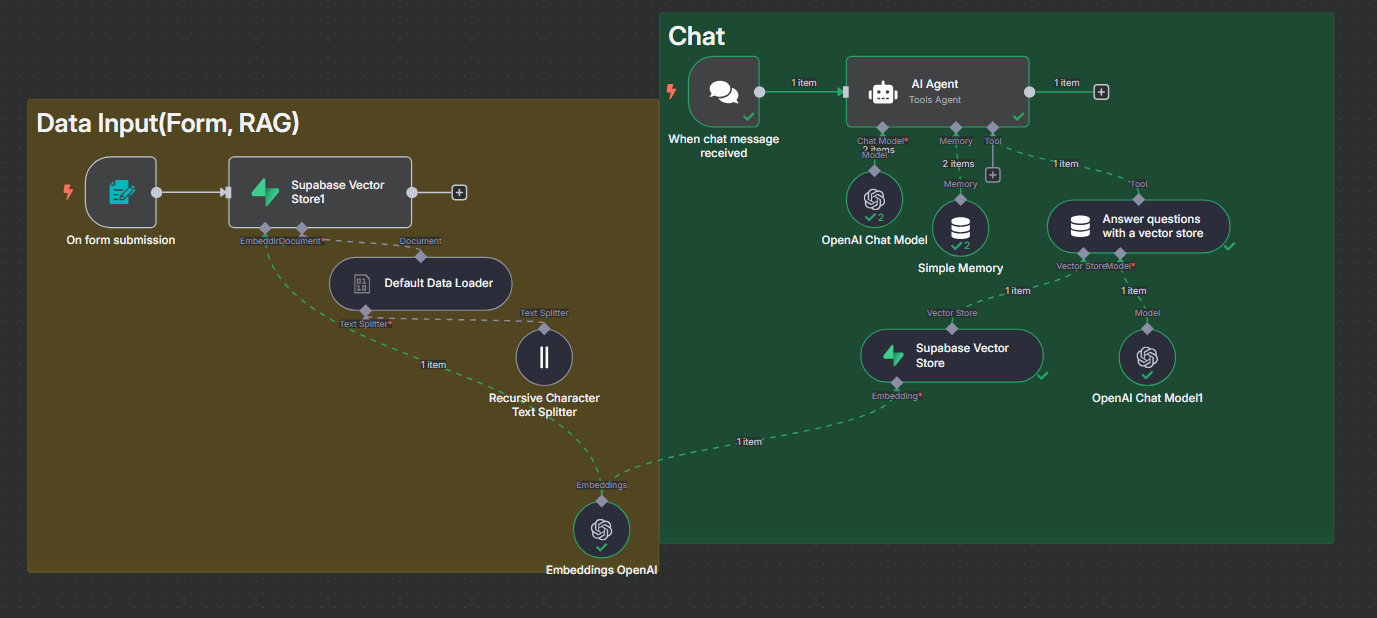

전체 흐름 개요
<관련 자료 첨부>
- 사용자가 질문 입력
- AI Agent가 질의 내용 분석
- 관련 질문이면 Vector Store 질의
- 유사 Chunk 검색 → 응답 생성
- 이전 대화 맥락도 메모리에 저장
구현 단계
1. Chat, 기본 챗봇 인터페이스 구성
- Chat Trigger 노드로 챗 입력을 받을 수 있도록 설정
- AI Agent 노드와 연결해 OpenAI GPT 모델을 사용
- 기본적인 질의응답 기능 구현 완료


2. Data Input(Form, RAG), 내 PDF 데이터를 벡터화(Embedding)

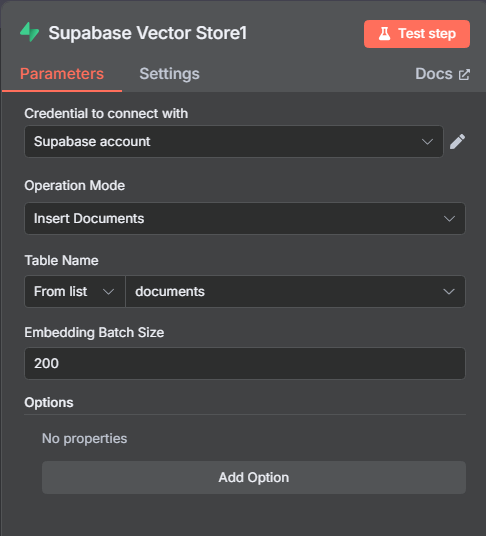
- 파일 업로드 노드 생성(- On form submission)
- Supabase 프로젝트 생성 (PostgreSQL 기반)
- LangChain용 SQL 템플릿 사용 → documents 테이블 자동 생성
- Supabase Credential = 회원가입후 > 우측 Project Setting 탭 > Data API
- Project URL과 Project API Keys - service_rolesecret 입력
- LangChain용 SQL 템플릿 = Table 생성
- SQL Editor 탭 > Quick Start 탭 > LangChain 선택 후 run
- Default SQL 템플릿 사용시 Table Editor에 documents 생성확인



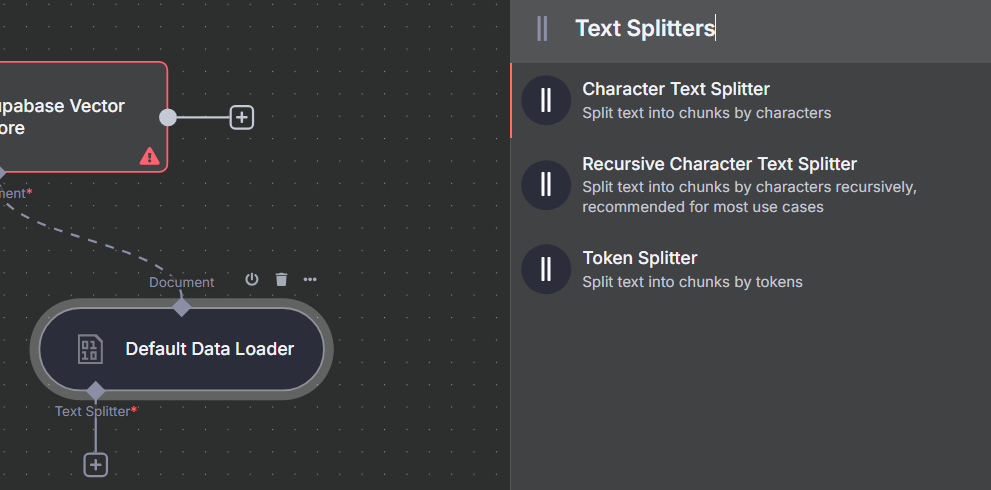
3. Data Input(Form, RAG), Data Loader 및 Text Splitter 설정
- Default Data Loader에서 입력 타입은 Binary 선택
→ 이유: 단순히 Text를 읽어오는 것이 아니라 File을 가져오기 때문 - Text Splitter는 Recursive Character Text Splitter 선택
→ 이유: 문맥이나 문장 단위가 끊기지 않도록 의미 단위로 분할 가능
→ 설정: chunk size = 1000, overlap = 100
(중복 100자를 앞뒤로 겹쳐 문맥 유지를 도모)

Embedding 관련 파라미터
| 항목 | 설명 |
|
Recursive Character Text Splitter, Chunk size
|
한 덩어리로 자를 글자 수 (예: 1000자) |
| Recursive Character Text Splitter , Overlap | 앞뒤 문단의 중첩 범위 (예: 200자) |
| Embeddings OpenAI, Embedding 모델 | text-embedding-ada-002 등 OpenAI 모델 사용 |
<Vector Store 사용 이유>
- LLM은 “무엇이 중요한가”를 판단하려면 문서 전체가 아닌 핵심 문단이 필요함
- Vector Store를 사용하면:
- 문서를 벡터화(Embedding) 하여 저장
- 질문을 동일하게 임베딩 → 유사도 기반으로 문단 검색(유클리안, 코사인유사도 .. )
- 가장 관련도 높은 정보만 AI에게 전달하여 정확도 향상
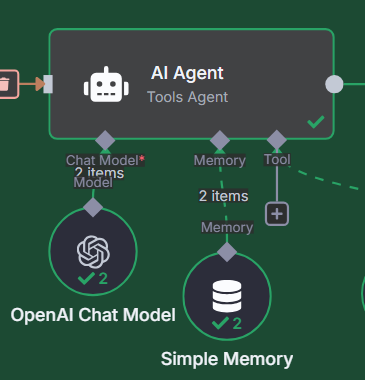
4. 메모리 기능 추가
- Window Buffer Memory 또는 Postgres Chat Memory 연결
- 동일 세션 내에서 이전 질문-답변 내역을 유지
- "방금 말한 조항 번호가 뭐야?" 같은 흐름 질문에도 자연스럽게 응답 가능

5. Test 진행 및 결과
질문 예시
Q. 2025년 세법 개정안에 따르면, 금융소득 종합과세 기준 금액은?→ ChatGPT 응답(실제 Data와 동일): 2025년 세법 개정안에 따르면, 금융소득 종합과세 기준 금액 - 2000만원
- 새로 만든 개정안, RAG Sample Data ( > 2025년 2000만원에서 1500만원으로 낮춰졌다 기입)


초기 결과 (PDF 문서 없이):
→ 엉뚱한 답변 or 헛소리 (hallucination)

RAG Sample Data, PDF Embedding 후 결과:
→ 정확하게 2025년 세법 개정안에 따르면, 금융소득 종합과세 기준 금액은 1500만 원으로 낮아졌습니다.

회고
- RAG 구조가 아니면 절대 나올 수 없는 수준의 정확도였다
- n8n으로 AI 챗봇 인터페이스와 워크플로우를 쉽게 구성할 수 있었고
- Supabase는 무료로도 쓸 수 있어 개인 프로젝트에 최적화
📌 확장 아이디어
- 지금은 Data를 첨부 후 참조하는 방식이겠지만, 이미 내부 Data가 Database화 되어있다면
맞춤 응답 시스템으로 사용할 수 있겠다.
- 또한, 해당 출처(Data) 안에서만 대답할 수 있게 요쳥 가능
- Slack, Discord 등과 연결하여 팀원 대상 Q&A 챗봇으로 활용
- 내부 가이드 문서 자동 질의 응답 시스템
- 고객 응대를 위한 FAQ 챗봇
'Automation Tool' 카테고리의 다른 글
| Oracle Cloud에 n8n 배포 (1) | 2025.05.21 |
|---|---|
| n8n + Slack 연동 방법 (1) | 2025.05.16 |
| n8n + GPTs, AI비서 만들기(Google Calendar, 일정(Event) 잡기) (0) | 2025.05.12 |
| n8n + GPTs, AI비서 만들기(Gmail, Send mail) (0) | 2025.05.12 |
| n8n, Google Credential 연동하기 (0) | 2025.05.12 |




댓글