
📅 Sense Stock 개발 일지 (2025-07-09)
n8n, 사용자 질의 기반 경제/시장/주식 분석 자동화 파이프라인 구축 중 진행한 작업들을 정리합니다.
오늘은 Playwright와 BeautifulSoup을 조합해 경제/실적 캘린더, 섹터/티커 정보 크롤링 파이프라인을 구축했습니다.
❓ 지난번 고민 내용
- 각 Data 취합 로직 구현 및 변동률 기준(예: ±3%) 이상일 때만 뉴스 요약 흐름을 실행할지
- 각 Data 취합 로직 구현 => 금일 진행
- 종목 추천 흐름 설계 시, 어떤 데이터 기준으로 필터링할지
뉴스 요약만으로는 부족했다.
경제 지표 일정이나 섹터 퍼포먼스, 개별 티커 정보 같은 기초 데이터를 자동으로 수집하지 않으면, 매번 브라우저를 열어 수동 확인해야 했다. 특히 Investing.com이나 Finviz처럼 유용한 사이트가 있어도, Lazy Load나 JavaScript 렌더링 구조 때문에 단순 requests 기반 크롤러로는 한계가 분명했다.
그래서 Playwright + BeautifulSoup 조합을 쓰는 구조로 전환하게 되었다.
+ Docker beautifulsoup4 Install 진행
🐳 Dockerfile 설정
- beautifulsoup4는 기본 Docker 이미지에 없기 때문에 따로 설치 필요
- 개발 중엔 docker exec -it 컨테이너명 sh → pip install beautifulsoup4 식으로 빠르게 테스트 가능하지만, 운영 배포에서는 반드시 Dockerfile에 반영해야 함
⚠️ 주의: 임시 설치는 Container 재시작 시 초기화됨
개발 단계 (빠른 테스트용 = Container 재시작 시 초기화)
docker exec -it n8n-container bash
pip install beautifulsoup4운영 단계 (안정성 확보)
# Dockerfile에 직접 추가
RUN pip install beautifulsoup4💡 왜 Playwright + bs4 조합이 필요한가?
처음엔 그냥 Playwright에서 page.query_selector() 등으로 DOM에서 직접 값을 꺼내려 했는데,
이 방식은 직관적으로 복잡하고 유지보수가 어려웠다. 이유는 JS...(난 Python 원툴이란 말이다🥴, JS는 파싱정도만 ㅋㅋ,
Playwright도 Python을 지원하지만.. Beautifulsoup이 좀 더 익숙하기도 했다)
반면 page.content()로 전체 HTML을 받아서 BeautifulSoup으로 파싱하면 다음과 같은 장점이 있다
- HTML 구조 기반 접근이 훨씬 직관적
- 데이터 추출이 구조적으로 깔끔함 (select_one, find_all 등)
- Python 환경에서 더 익숙하게 컨트롤 가능
즉, Playwright는 렌더링 담당, BeautifulSoup은 파싱 담당으로 역할을 분리해 효율을 높였다.
- Playwright: 브라우저 자동화, JS 렌더링, 봇 탐지 우회
- BeautifulSoup: HTML 파싱, 구조적 데이터 추출, Python 친화적 API
Playwright → JavaScript 렌더링 완료 → HTML 추출
BeautifulSoup → CSS 선택자로 데이터 추출 → 구조화된 결과 반환
✅ 주요 작업 리스트
- 경제 Calendar / 실적 Calendar 자동 수집
- Sector Performance 수집 및 Daily Sector Performance 파싱(일별 수집)
- Ticker별 정보 추출 (n8n, Execute Command Node - CLI 인자 값(Ticker) 기입)
- Dockerfile에 BeautifulSoup4 추가 & 운영 환경 고려
📑 데이터 수집 출처



1. 경제지표 / 실적 발표 일정
- Investing.com 경제 / 실적 캘린더
경제: https://kr.investing.com/economic-calendar/
실적: https://kr.investing.com/earnings-calendar/
→ 발표 시점, 영향도, 국가별 정렬 가능
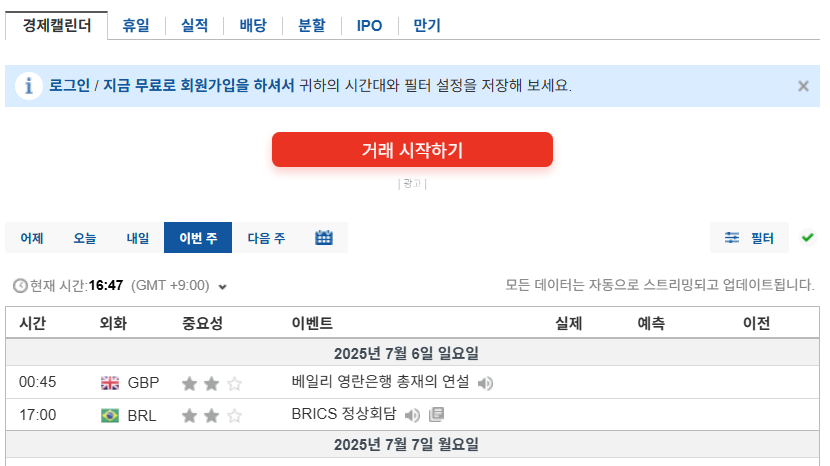
🔹 경제/실적 캘린더 통합
- 경제 캘린더 (이번 주 / 다음 주)와 실적 캘린더 데이터를 수집
- 날짜별로 구분된 JSON 구조로 가공
- `Calendar Parsing` 노드에서 모든 캘린더 정보를 병합하여 단일 데이터로 정리
- 이후 AI 요약, 일정 알림, 투자 판단 등에 활용 가능

html = await page.content()
soup = BeautifulSoup(html, "html.parser")
table = soup.select_one("table.common-table")
for row in table.select("tbody tr"):
# 미국 국기만 필터링
if "United_States" not in row.get("class", []):
continue
# 항목별 값 추출
cols = [td.get_text(strip=True) for td in row.select("td")]
- 날짜별로 grouping 하고
- "이벤트", "중요도", "예측값" 등 주요 항목만 정리해 JSON으로 변환했다.
📅 경제/실적 캘린더 파싱 방식
기간 카테고리 구분:
어제 / 오늘 / 내일 / 이번주 / 다음주
- 이번 주 기준 전체 일정에서 미국 이벤트만 필터링
- 오늘/내일만 따로 뽑는 기능도 구현 예정
- 다음 주 일정도 조건 분기로 처리 가능하게 설계
2. 섹터/산업별 데이터
- Finviz Sector Overview
https://finviz.com/groups.ashx
→ 섹터별 퍼포먼스, 티커 분포 확인 가능
→ 일간, 주간, 월간, 분기별 기준 분류도 가능
🔹 섹터 퍼포먼스 요약
- 전체 섹터 데이터 중 주요 필드만 추출 (예: Perf Week, Change 등)
- `Sector Daily` 형식으로 가공하여 Slack 또는 보고서에 활용
- 시각화나 정렬 기반 분석에 적합한 형태로 변환
3. Ticker 기반 종목 상세 정보
- Finviz Screener
https://finviz.com/screener.ashx?v=111&t=TSLA
→ 정확한 티커명을 활용해 종목 스크래핑 가능
→ 추후 종목 추천 시 유용할 예정
🔹 Ticker 정보 정제
- 사용자 입력 또는 수집된 데이터를 전처리하여 필요한 필드만 남김
- Ticker, Name, Sector 등 핵심 항목 추출
- 이후 단계에서 AI 분석, 뉴스 크롤링 등으로 활용 가능
<Finviz 추출 데이터 참조확인>
https://cord-ai.tistory.com/239
Ticker 기반 종목 상세 정보, Process는 좀 다르게 설계를 했는데,
후에 종목 추천으로 결과값을 가져오는게 있다면, 종목 관련 데이터를 참조하기 위해서 아래처럼 구현했다
🧩 Ticker 정보 추출 구조
n8n에서 Input으로 Ticker를 입력받고, 해당 Ticker를 기반으로 Python 스크립트를 실행하는 구조
## <<n8n, Execute Command Node>>
python3 파일경로/stock_info.py {{ $json["ticker"] }}
## <<stock_info.py>>
if __name__ == "__main__":
ticker = sys.argv[1]
result = asyncio.run(extract_stock_info(ticker))
print(json.dumps(result)) # 👉 n8n에서 stdout으로 받음
🚨 진행중 이슈 정리(장문주의)
❓ 왜 브라우저 Context 설정이 필요할까?
자동화 탐지를 피하기 위함.
사이트에 따라 headless 모드나 특정 User-Agent에서 렌더링을 생략하거나, 403을 띄우기도 하기 때문에
- 실제 브라우저처럼 동작하는 환경을 흉내 내는 것
- 특히 Playwright의 context 옵션, UA 지정, 쿠키 설정 등이 탐지 우회를 위한 핵심
await browser.new_context(user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.3 ...)
❓ viewport={"width": 1280, "height": 800} 설정 이유
Playwright는 기본적으로 모바일 디바이스처럼 좁은 뷰포트를 가질 수 있기 때문에, 페이지가 데스크탑 기준으로 완전히 로드되지 않는 경우가 있다.
이 설정을 통해 데스크탑 해상도 환경을 흉내 내며, 사이트가 데스크탑용 DOM 구조를 불러오도록 유도한다.
- 실제로 table, chart, filter 요소들이 뷰포트 너비에 따라 비동기 렌더링 방식이 달라지는 경우가 많다.
- 특히 반응형 UI에서는 작은 뷰포트일 경우 일부 요소가 생략되거나 hidden 처리되기도 한다.
결론적으로, 신뢰할 수 있는 HTML 구조를 확보하기 위해선 기본 뷰포트 설정이 중요하다.
❓ await page.wait_for_selector(...)를 쓰는 이유
Playwright는 브라우저에서 페이지를 불러오자마자 다음 작업으로 넘어간다.
하지만 JavaScript로 렌더링되는 동적 요소들은 아직 생성되지 않았을 수 있다.
그래서 특정 셀렉터가 DOM에 등장할 때까지 기다리는 await page.wait_for_selector(...)를 걸어두면,
- JavaScript 렌더링이 끝났는지 확인 가능
- 크롤링 타이밍을 명확히 제어할 수 있음
예를 들어 await page.wait_for_selector("table.common-table")를 쓰면
그 테이블이 등장할 때까지 기다렸다가 HTML을 파싱하게 된다.
❓ async def를 왜 쓰는가?
Playwright는 내부적으로 비동기 작업(JS 실행, 페이지 이동 등)이 많기 때문에, 동기 방식보다 빠르고 유연한 흐름 제어가 필요함.
즉, 페이지 렌더링을 기다리고 → 요소를 탐색하고 → 다시 렌더링 기다리고... 이 모든 걸 효율적으로 처리하기 위해 async/await 구조를 사용.
예시
<await 없는 동기식>
import time
def task(name, delay):
print(f"{name} 시작")
time.sleep(delay)
print(f"{name} 완료")
def run_tasks():
task("🍜 라면 끓이기", 3)
task("📧 이메일 확인", 2)
task("📁 파일 저장", 1)
run_tasks()
## <<결과>>
🍜 라면 끓이기 시작
(3초 기다림)
🍜 라면 끓이기 완료
📧 이메일 확인 시작
(2초 기다림)
📧 이메일 확인 완료
...😩 작업은 순서대로만 진행 → 전체 6초 소요
✅ 비동기 코드로 바꾸면?
import asyncio
async def task(name, delay):
print(f"{name} 시작")
await asyncio.sleep(delay)
print(f"{name} 완료")
async def run_tasks():
await asyncio.gather(
task("🍜 라면 끓이기", 3),
task("📧 이메일 확인", 2),
task("📁 파일 저장", 1),
)
asyncio.run(run_tasks())
<<결과>>
🍜 라면 끓이기 시작
📧 이메일 확인 시작
📁 파일 저장 시작
📁 파일 저장 완료 (1초 후)
📧 이메일 확인 완료 (2초 후)
🍜 라면 끓이기 완료 (3초 후)🚀 동시에 진행됨! → 전체 3초만에 끝
✅ 요점 정리
기다리는 동안 할 수 있는 것들 (예시) 설명
| 다른 웹 요청 보내기 | API, 웹페이지, 데이터 서버 등 |
| 사용자 입력 처리 | 브라우저 자동화 중 다른 탭 조작 |
| 파일 저장 / 로깅 처리 | 응답 기다리는 동안 처리 가능 |
| 여러 URL 크롤링 동시에 | 100개 페이지 동시 크롤링도 가능 |
“Playwright에서 여러 탭을 async로 동시에 크롤링”
# 병렬 실행
await asyncio.gather(*tasks)
"I/O(입출력)가 느릴 땐 기다리기만 하지 말고,
그 시간에 다른 일도 같이 처리하자!"
라는 똑똑한 방식입니다.
🖥 headless 모드에 따른 차이 (Local vs n8n)
| 모드 | 설명 | 용도 |
| headless=False | 실제 브라우저처럼 UI 띄움 | 시각 확인 가능, 렌더링 안정적 |
| headless=True | 브라우저 UI 없이 백그라운드 실행 | 속도 빠름, 일반 자동화에 적합 |
→ Local에서 디버깅 중일 땐 False,
→ 운영 자동화(n8n 등)에선 True를 기본으로 쓴다.
❓ 그런데 왜 n8n에선 headless=True가 필요할까?
몇몇 사이트는 자동화 탐지(bot detection) 방지 로직이 걸려 있다.
- Playwright가 headless로 접근하면, User-Agent나 브라우저 속성에서 비정상적인 요청으로 인식
- 그 결과 JS 기반 DOM을 아예 렌더링하지 않거나, 403 에러를 뱉는 경우도 있음
이럴 땐 다음과 같은 조건 조합이 해결책이 된다(브라우저 설정 우회)
browser = await playwright.chromium.launch(headless=False)
context = await browser.new_context(user_agent=...)
핵심 요인: headless=False의 숨겨진 효과
✅ 실제 브라우저처럼 렌더링
- JS를 눈으로 보이는 브라우저처럼 전부 렌더링
- DOM 완성도가 높아지고, wait_until="domcontentloaded"만 해도 대부분 구조가 잡힘
✅ headless=True의 한계
- 백그라운드에서 작동 → 렌더링 타이밍이 불안정
- 특히 div.futures.pt-2.5처럼 JS로 나중에 생기는 요소는 렌더링되지 않을 가능성 높음
✅ print(html)이 도와준 이유
- await page.content() 직후 print(html)을 쓰면,
출력 자체에 시간이 걸리기 때문에 DOM 렌더링 완료까지 추가 시간이 생긴다 - 이게 일종의 간접적 delay() 역할을 한 셈
✅ 그래서 초반 코드가 잘 작동했던 이유
| 항목 | 설정 | 효과 |
| headless=False | 시각적 브라우저 실행 | 시각 확인 가능, 렌더링 안정적 |
| print(html) | 출력 지연 | 렌더링 타이밍 확보 |
❓ 다음 단계에서 고민 중인 것들
이제는 수집한 데이터들을 실제로 최종 응답에 어떻게 활용할 것인지를 실험해봐야 할 시점이다.
단순히 데이터를 수집하는 걸 넘어서, 어떤 정보가 어떤 맥락에서 사용될지 참조 방식 설계가 핵심이 될 것 같다.
- 오늘 / 내일 일정만 따로 뽑아주는 기능 구현 필요.
- 다음 주 일정까지 조건 분기로 자동 필터링되도록 확장할 수 있을 듯.
이걸 바탕으로 결과물을 리포트 형태로 나누는 구상도 하고 있다
- Daily
- 시장 전반 요약: 주요 이슈 + 섹터/지수 변동률
- Weekly
- 경제 캘린더 요약, 섹터별 성과, 주간 이벤트 브리핑
- Monthly / Quarterly
- 실적 발표, 정책 발표 일정, 시장 사이클 요약 등 리포트화
데이터는 다 모았으니, 이제 남은 건 이걸 어떻게 똑똑하게 꺼내 쓸지, 그리고 어디까지 자동화할 수 있을지에 대한 설계다.
그게 다음 스텝의 핵심 과제가 될 것 같다.
'Automation Tool > n8n Project' 카테고리의 다른 글
| Sense Stock, D+18 (0) | 2025.07.15 |
|---|---|
| Sense Stock, D+17 (0) | 2025.07.11 |
| Sense Stock, D+15 (0) | 2025.07.07 |
| Sense Stock 개발 회고, 두 번째 (1) | 2025.07.04 |
| Sense Stock, D+14 (0) | 2025.07.01 |




댓글