- 분류모델을 할 때에는Confusion matrix 를 만들고 해석할 수 있습니다. (=해당 matrix로 설명해야되)
- 정밀도, 재현율 을 이해하고 사용할 수 있습니다.
- ROC curve, AUC 점수 를 이해하고 사용할 수 있습니다.


* True / False ==> 예측이 정확했는지
(판단을 올바르게 했다)
* Positive / Negative ==> 모델을 통한 예측값
(판단자가 그렇다 판별)
- 병원에서 초기 암진단을 하는 경우?
- 넷플릭스에서 영화추천을 해주는 경우?
재현율이 중요 지표인 경우는 암 판단 모델이나 금융 사기 적발 모델과 같이 실제 Positive 양성 데이터를 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우이다.
따라서 보통 재현율이 정밀도보다 상대적으로 중요한 업무가 많지만, 스팸메일 여부를 판단하는 모델과 같은 경우는 정밀도가 더 중요한 지표이다.
*Evaluation
from sklearn.metrics import classification_report
classification_report(y_val, y_pred)
# 모든 평가지표 score 확인 해볼 수 있음
### confusion metrics
from sklearn.metrics import plot_confusion_matrix
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
pcm = plot_confusion_matrix(pipe, X_val, y_val,
cmap=plt.cm.Blues,
ax=ax);
plt.title(f'Confusion matrix, n = {len(y_val)}', fontsize=15)
plt.show()
TP = pcm[0][0] #둘다 Anomal, 0이며 예측값이 positive(이상값)이다.
FN = pcm[0][1] #실제값과 예측값이 달랐으며, 예측값이 negative(정상값)이다.
FP = pcm[1][0] #실제값과 예측값이 달랐으며, 예측값이 postive(이상값)이다.
TN = pcm[1][1] #둘다 nomal, 1이며 예측값이 negative(정상값)이다.| Predict | |||
| Actual | 1000 | 정상판정 | 암판정 |
| 정상환자 | 988 (TP) | 2 (FN) | |
| 암환자 | 1 (FP) | 9 (TN) |
|
1. 정확도 ( Accuracy )
= 전체 범주 accuracy_score / data가 불균형일 경우 정확하지 않다 = f1_score확인
== 학습시켰을 때 1000명 -> 1000명을 정상이라 했을 때 990명은 맞춤
=> accuracy 99%이지만 암환자를 못찾음
(TP + TN) / total
total= 총 예측 수
# 정밀도와 재현율 Trade off
2. 정밀도 ( Precision ) = Positive로 예측한 경우 올바르게 Positive 맞춘 비율
==> 예측 입장에서 ( spam 메일 나눌때 ) TP / (TP + FP )
= 암판정에서만 판단 81%
ex) 양성 항목 정답율
3. 재현율 ( Recall = 민감도) = 실제 Positive 예측한 경우 올바르게 Positive 맞춘 비율
==> 실제 정답 입장에서( 암환자인지를 예측할때 ) TP / (TP + FN)
= 실제 암환자에서만 판단 90%
*특이도*
심장질환이 없는 사람중에 올바르게 분류된 사람들의 비율
TN / (TN + FP)
4. F1_score = 정밀도와 재현율의 조화 평균 (= 불균형 data에서의 주요 척도 )
F1 Score는 예측 오류 개수만 관련되는 것이 아니라 발생한 오류의 종류도 관여하게 된다
==> 정밀도 재현율 둘다 중요하다 판단되면 쓰는 평가지표
(= 정밀도 재현율이 비슷해질때(균등하게 클때 값이 큼)
# A B C D 가 있는데
model1 = A 100 B C D 골고루 맞춤
model2 = A 200 A 만 잘맞춤
==> 정확도로 봤을 때는 model2가 높게 나오지만 모댈2가 성능이 좋다고 할 수 없음
so, f1_score 사용 (= 이런경우를 imbalance라고 함 )
5. F_Beta 정밀도에 주어지는 가중치 (= beta가 1인 경우를 f1_score)
재현율이 더 중요하다 싶으면 beta 1 이상
정밀도가 더 중요하다 싶으면 beta 0~ 1
EX) Beta= 1 , (정밀도 : 0.6, 재현율 : 0.4)=0.48 == (재현율 :0.6, 정밀도 : 0.4) = 0.48
==> 순서가 바뀌어도 값은 같다
but Beta= 2, (정밀도 : 0.6, 재현율 : 0.4)=0.43
Beta= 2, (정밀도 : 0.4, 재현율 : 0.6)=0.55 # 값이 다름
==> Beta 값에 따라 값이 다른데 재현율(Recall)에 더 의존되있다 볼 수 있다.
# 예측확률과 임계값
-> 필요한 범주의 정밀도나 재현율을 조정하여 최소한의 백신접종으로 최대한의 결과 얻을 수 있음
=> 모든 임계값을 한눈에 보고 모델을 평가( ROC Curve )
*임계값을 낮추면 범주 0에 대한 정밀도는 올라간다
######## Positive의 범주 ############
pipe_ord.predict_proba(X_val)[:,1]
=> 0과1을 분류하는 모델이 있는데 임계값이 0.5라면 0.5 이상은 1 / 이하면 0으로 분류
*임계값(Thresholds) = 기준 0.5로 잡지만 문제에 따라 달라짐
==> 임계값에 따라서 정밀도 재현율이 달라짐
so, 적절한 임계값이 중요, 임계값에 따라 정밀도, 재현율 Trade off( 반비례 )
* 0과 1 정밀도와 재현율
1에대한
==> 임계값 ↑ = 정밀도↑ 재현율↓
임계값 ↓ = 정밀도↓ 재현율↑
0에대한
==> 임계값 ↑ = 정밀도↓ 재현율↑
임계값 ↓ = 정밀도↑ 재현율↓
*임계값을 낮출 경우
사용자가 임계값을 낮은 기준으로 조절하면 분류기는 True라고 응답하는 경우가 많아집니다.
즉, TP와 FP가 높아지는 현상이 발생합니다.
(True라고 응답한 결과들 중에서 실제 True인 경우가 있으므로 둘 다 상승합니다.)
이 경우 FN은 줄어드니 (상대적으로 FP와 TP가 많아지므로) 재현율이 올라가는 현상이 발생합니다.
*임계값을 높일 경우
반대로 사용자가 임계값을 높은 기준으로 조절하면 분류기는 False라고 응답하는 경우가 많아집니다.
즉 TN과 FN이 높아집니다.
또한 분류기는 높은 신뢰 점수를 갖는 입력에만 True라고 응답하니 FP는 줄어들고 TP가 높아집니다.
* ROC, AUC ( Receiver Operation Characteristic, Area Under the Curve)
목표 점수는 Positive Class의 확률 추정치(proba), 신뢰도 값 또는 임계 값이 아닌
결정 측정치 (일부 분류기의 "decision_function"에 의해 반환 됨) 일 수 있습니다.
ROC curve는 이진분류문제에서 사용할 수 있습니다.
다중분류문제에서는 각 클래스를 이진클래스 분류문제로 변환(One Vs All)하여 구할 수 있습니다.
- 3-class(A, B, C) 문제 -> A vs (B,C), B vs (A,C), C vs (A,B) 로 나누어 수행
각 범주를 예측하는 기준이 되는 임계값의 위치에 따라 정밀도나 재현율이 달라지기 때문에 문제의 상황에 따라
적절한 임계값을 선택할 필요성이 있습니다.
이진 분류문제에서는 ROC curve와 AUC 점수를 잘 활용하면 좋은 결과를 만들어냄
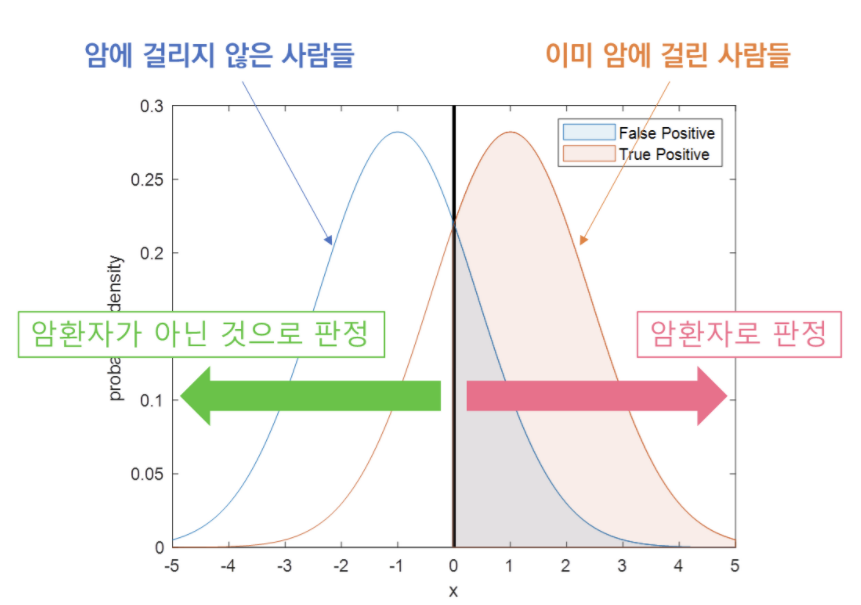

재현율을 높이기 위해서는 Positive로 판단하는 임계값을 계속 낮추어 모두 Positive로 판단하게 할 수 있음
==> 암이 아닌데도 다 암이라고 판정을 함
재현율은 최대화 하고 위양성률(FPR) 은 최소화 하는 임계값이 최적의 임계값 ==> roc curve를 생각하면됨
임계치에 따라 TPR, FPR 비례함 ==> TP , FP가 같이 커지거나(임계치가 작을때), 작아짐(임계치가 클때)
- TPR : True Positive Rate (=민감도, true accept rate) == 재현율
1인 케이스에 대해 1로 잘 예측한 비율.(암환자를 진찰해서 암이라고 진단 함)
- FPR : False Positive Rate (=1-특이도, false accept rate) == FP / (FP +TN)
0인 케이스에 대해 1로 잘못 예측한 비율.(암환자가 아닌데 암이라고 진단 함)
- TNR : True Negative Rate == 특이도, TN / (FP + TN)
- 민감도 : 1인 케이스에 대해 1로 잘 예측한 것.
- 특이도 : 0인 케이스에 대해 0으로 잘 예측한 것. True Neagative
출처: Attribution-NonCommercial 4.0 International
*현의 휨 정도는 구별을 잘됬느냐 안됬느냐를 판단
= TP와 FP가 구별이 잘되면 AUC면적이 커짐
= 즉, ROC Curve가 좌상단에 붙어 있다
= 좋은 모델이다 판단
from sklearn.metrics import roc_curve
# roc_curve(타겟값, prob of 1)
fpr, tpr, thresholds = roc_curve(y_val, y_pred_proba)
# threshold 최대값의 인덱스, np.argmax()
optimal_idx = np.argmax(tpr - fpr)
optimal_threshold = thresholds[optimal_idx]
from sklearn.metrics import roc_auc_score
auc_score = roc_auc_score(y_val, y_pred_proba)
auc_score'Data Analysis, DA > Tree based Model' 카테고리의 다른 글
| n224 Resampling(Cross Validation / K- hold out / BootStrap) (0) | 2021.06.20 |
|---|---|
| n222 RandomForest/ OrdinalEncoder (0) | 2021.06.19 |
| n221 Decision Trees, gini, entropy (0) | 2021.06.19 |



댓글