- 모델선택을 위한 교차검증 방법을 이해하고 활용할 수 있다.
- 하이퍼파라미터를 최적화하여 모델의 성능을 향상시킬 수 있다.
- 왜 train validation test로 나누나?
* 모델 선택 ( Model Selection )
- 우리 문제를 풀기위해 어떤 학습 모델을 사용해야 할 것인지?
- 어떤 하이퍼파라미터를 사용할 것인지?
==> 데이터 크기에 대한 문제, 모델 선택에 대한 문제를 해결하기 위해
사용 하는 방법 중 한가지 Cross validation (= 시계열 데이터는 안되)
# 데이터셋 분리
from sklearn.model_selection import train_test_split
X_train_val, X_test, y_train_val, y_test = train_test_split(
X, y, test_size=10000
, stratify=y
, random_state=2)
X_train, X_val, y_train, y_val = train_test_split(
X_train_val, y_train_val, test_size=10000
, stratify=y_train_val
, random_state=42)
print('X_train shape', X_train.shape)
print('y_train shape', y_train.shape)
print('X_val shape', X_val.shape)
print('y_val shape', y_val.shape)
print('X_test shape', X_test.shape)
print('y_test shape', y_test.shape)==> hold-out cross-validation
* TargetEncoder
범주형 변수 인코더로, 타겟값을 특성의 범주별로 평균내어 그 값으로 인코딩
Resampling 기법(K-fold, BootStrap)
리샘플링은 모집단의 분포 형태를 알 수 없을 때 주로 사용하는 방법이다.
즉, 모분포를 알 수 없으므로 일반적인 통계적 공식들을 사용하기 힘들 때, 현재 갖고 있는 데이터를 이용하여 모분포와 비슷할 것으로 추정되는 분포를 만들어 보자는 것이다.
리샘플링은 가지고 있는 샘플에서 다시 샘플 부분집합을 뽑아서 통계량의 변동성(variability of statistics)을 확인하는 것이라고 할 수 있다. 즉, 같은 샘플을 여러 번 사용해서 성능을 측정하는 방식이다.
리샘플링은 표본을 추출하면서 원래 데이터 셋을 복원하기 때문에 이를 통해서 모집단의 분포에 어떤 가정도 필요 없이 표본만으로 추론이 가능하다는 장점이 있다.
* BootStrap
= Bootstrap은 기존의 data set 1개에서 N번의 simulation을 통해 새로운 data set N개를 sampling하는 방법이다.
= 모수의 분포를 추정하는 방법 중 하나는, 현재 가진 표본에서 추가적으로 표본을 복원추출하고 각 표본에 대한 통계량을 다시 계산하는 것이다. 부트스트랩이 여기에 해당하며, 여러번의 무작위 추출을 통해, 평균의 신뢰구간을 구할 수 있다.
https://cord-ai.tistory.com/20
n222 RandomForest/ OrdinalEncoder
랜덤포레스트 모델을 이해하고 문제에 적용할 수 있습니다. 순서형인코딩(Ordinal encoding) 과 원핫인코딩을 구분하여 사용할 수 있습니다. 범주형 변수의 인코딩 방법이 트리모델과 선형회귀 모델
cord-ai.tistory.com
예를 들어, 어떤 분포에서 생성된 것인지 모르는 n개의 데이터가 있을 때 여기에서 sample median을 구할 수 있는데, sample median의 분산을 추정하는데 bootstrap을 사용할 수 있다.
이때 sample median은 population median에 대한 estimator이고, 이 estimator의 uncertainty를 측정하기 위해 분산을 구하는 것이다. Bootstrap을 이용하지 않는다면 우리는 n개의 데이터로부터 1개의 sample median만 알 수 있다. 하지만 bootstrap sampling을 B번 반복하면 B개의 data set (각각의 n개의 data point를 가짐)이 생성되고, 이로부터 B개의 sample median을 구할 수 있다.
출처 : https://bioinfoblog.tistory.com/126
* K-hold Cross-Validation( CV ) = 하이퍼파라미터 튜닝할때 쓰임
=( 데이터가 충분히 클 때 ==> 교차검증(hold-out)을 사용할 수도 있고
데이터가 작을 때 ==> K-hold Cross-validation을 쓸 수도 있음 )
ex) 데이터를 3등분으로 나누고 검증(1/3)과 훈련세트(2/3)를 총 세번 바꾸어가며 검증하는 것은 3-fold CV
# test data
모델이 데이터에서 어떻게 작동하는지 알기 위한 data
데이터를 훈련 세트와 테스트 세트로 나누는 이유는
새로운 데이터에 모델이 얼마나 잘 일반화되는지 측정하기 위해서
모델이 훈련 세트에 잘 맞는 것보다 학습 과정에 없던 데이터에 대해 예측을 얼마나 잘하느냐가 중요
model은 train data에 엄청 민감함
데이터의 수가 적은 경우에는 이 데이터 중의 일부인 검증 데이터의 수도 적기 때문에 검증 성능의 신뢰도가 떨어진다. 그렇다고 검증 데이터의 수를 증가시키면 학습용 데이터의 수가 적어지므로 정상적인 학습이 되지 않는다.
이러한 딜레마를 해결하기 위한 검증 방법이 K-폴드(K-fold) 교차검증 방법이다.
* K-hold
KFold는 train_test_split()을 몇번 반복하냐?
train_test_split는 데이터를 무작위로 나눔. 데이터를 무작위로 나눌 때
훈련 세트 ==> 분류하기 어려운 샘플
테스트세트 ==> 분류하기 쉬운 샘플
( 정확도는 높게나옴 / 반대로 어려운 샘플로 분류가 되면 정확도는 낮게 나옴 )
그러나 교차 검증을 사용하면 테스트 세트에 각 샘플이 정확하게 한번씩 들어가고
각 샘플은 폴드 중 하나에 속하며 각 폴드는 한번씩 테스트 세트가 됨
그렇기 때문에 교차 검증의 점수를 높이기 위해서는 데이터 셋에 있는 모든 샘플에 대해 모델이 잘 일반화 되어야 함
단점= 연산비용이 늘어남(=모델 K개를 만들면 데이터를 한번 나눴을 때보다 K배느려짐)
- 자세한 K-Fold 교차 검증 과정은 다음과 같다.
- 전체 데이터셋을 Training Set과 Test Set으로 나눈다.
- Training Set를 Traing Set + Validation Set으로 사용하기 위해 k개의 폴드로 나눈다.
- 첫 번째 폴드를 Validation Set으로 사용하고 나머지 폴드들을 Training Set으로 사용한다.
- 모델을 Training한 뒤, 첫 번 째 Validation Set으로 평가한다.
- 차례대로 다음 폴드를 Validation Set으로 사용하며 3번을 반복한다.
- 총 k 개의 성능 결과가 나오며, 이 k개의 평균을 해당 학습 모델의 성능이라고 한다.
* Cross-validation의 종류
(일반적으로)회귀에는 기본 k-겹 교차검증을 사용하고, 분류에는 StratifiedKFold를 사용한다.
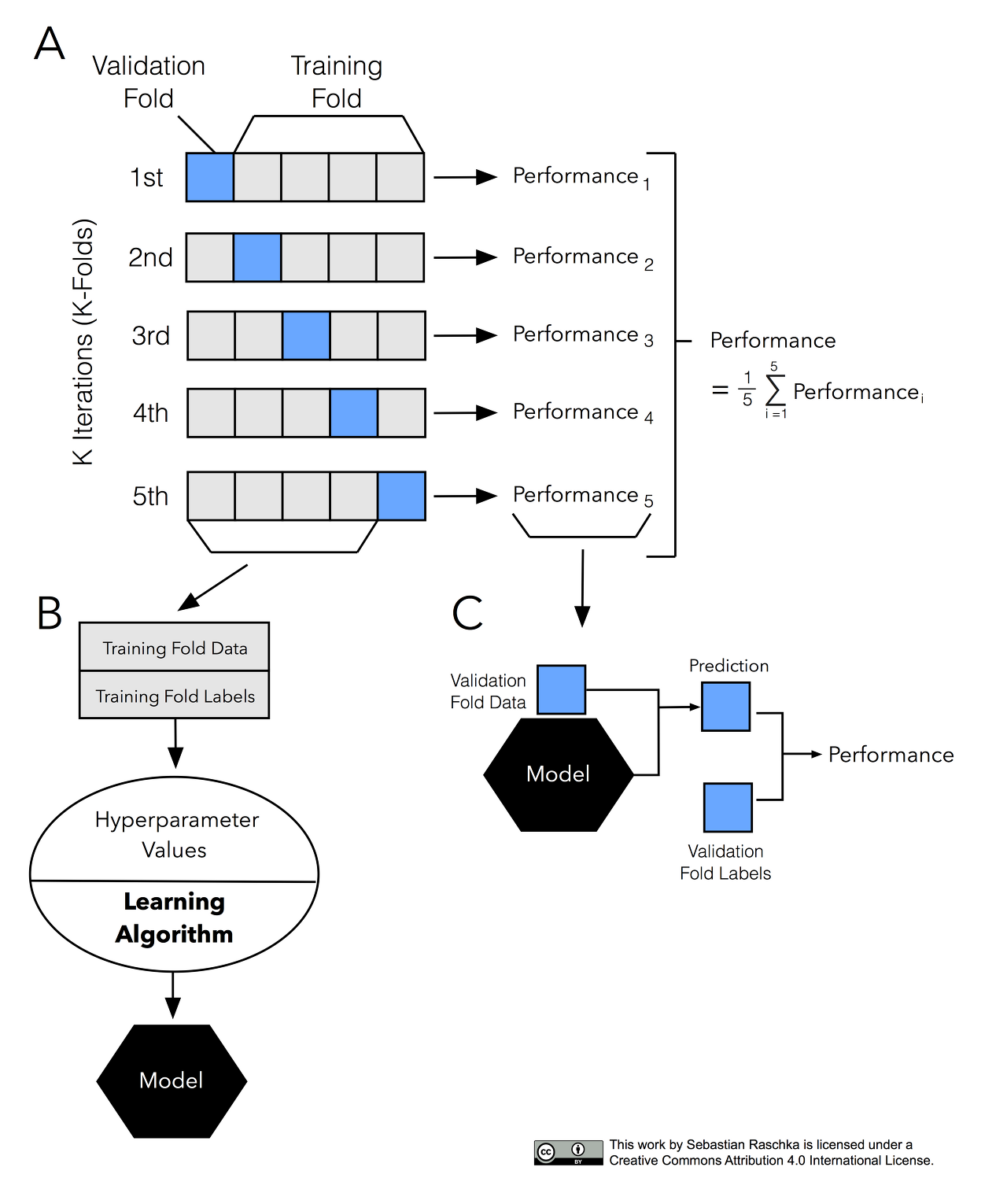
(1) 단순 교차검증 cross_val_score
- 데이터를 3등분으로 나누고 검증(1/3)과 훈련세트(2/3)를 총 세번 바꾸어가며 검증하는 것은 3-fold CV
==> 3-겹 교차검증
from sklearn.model_selection import cross_val_score
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
from sklearn.model_selection import ShuffleSplit
cv = ShuffleSplit(n_splits=5, test_size=0.3, random_state=0)
cross_val_score(clf, X, y, cv=cv)
# 단순교차검증에서는 ShuffleSplit 변수 지정(2) 계층별 k-겹 교차검증
데이터가 편항되어 있을 경우(몰려있을 경우) 단순 k-겹 교차검증을 사용하면 성능 평가가 잘 되지 않을 수 있다.
따라서 이럴 땐 stratified k-fold cross-validation을 사용한다.
(=클래스 비율이 데이터셋의 클래스 비율과 같도록 데이터를 나눔)
from sklearn.model_selection import StratifiedKFold
kfold= StratifiedKFold(n_splits=10, shuffle=True, random_state=1)
score= cross_val_score(pipe, X_train, y_train, cv=kfold)
# 계층별교차검증에서 '교차검증분할'을 할려면 KFold의 shuffle 매개변수를 True
또한, cross_val_score 함수에는 KFold의 매개변수를 제어할 수가 없으므로,
따로 KFold 객체를 만들고 매개변수를 조정한 다음에 cross_val_score의 cv 매개변수에 넣어야 한다
(3) KFold 상세 조정
cv 매개변수에 교차 검증 분할기cross-vailidation splitter를 전달함으로써
데이터를 분할할 때 더 세밀하게 제어할 수 있음
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5) # KFold 객체 생성
logreg = LogisticRegression() # 모델 객체 생성
for n in [3, 5]:
kfold = KFold(n_splits=n)
scores = cross_val_score(logreg, iris.data, iris.target, cv=kfold)
kfold = KFold(n_splits=n, shuffle=True, random_state=0)
score= cross_val_score(pipe, X_train, y_train, cv=kfold)
or
for n in [3, 5]:
kfold = KFold(n_splits=n, shuffle=True, random_state=0)
scores = cross_val_score(logreg, iris.data, iris.target, cv=kfold)*하이퍼 파라미터 튜닝
- 최적화는 훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정이며,
- 일반화는 학습된 모델이 처음 본 데이터에서 얼마나 좋은 성능을 내는지를 이야기 합니다.
from sklearn.model_selection import validation_curve
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
DecisionTreeRegressor()
)
depth = range(1, 30, 2)
ts, vs = validation_curve(
pipe, X_train, y_train
, param_name='decisiontreeregressor__max_depth'
, param_range=depth, scoring='neg_mean_absolute_error'
, cv=3
, n_jobs=-1
)
'''
ts = train score
vs= validation score
'''
train_scores_mean = np.mean(-ts, axis=1)
validation_scores_mean = np.mean(-vs, axis=1)
# 훈련세트 검증곡선
ax.plot(depth, train_scores_mean, label='training error')
# 검증세트 검증곡선
ax.plot(depth, validation_scores_mean, label='validation error')

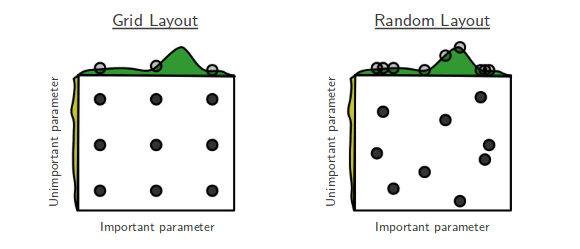
# Randomized Search CV
-검증하려는 하이퍼파라미터들의 값 범위를 지정해주면 무작위로 값을 지정해 그 조합을 모두 검증합니다.
# Grid Search CV
-검증하고 싶은 하이퍼파라미터들의 수치를 정해주고 그 조합을 모두 검증합니다.
from scipy.stats import randint, uniform
pipe = make_pipeline(
TargetEncoder(),
SimpleImputer(),
RandomForestRegressor(random_state=2)
)
dists = {
'targetencoder__smoothing': [2.,20.,50.,60.,100.,500.,1000.], # int로 넣으면 error(bug)
'targetencoder__min_samples_leaf': randint(1, 10),
'simpleimputer__strategy': ['mean', 'median'],
'randomforestregressor__n_estimators': randint(50, 500),
'randomforestregressor__max_depth': [5, 10, 15, 20, None],
'randomforestregressor__max_features': uniform(0, 1) # max_features
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50,
cv=3,
#stratifiedkfold = StratifiedKFold(n_splits=4, shuffle = True, random_state = 42)
scoring='neg_mean_absolute_error',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);
print('최적 하이퍼파라미터: ', clf.best_params_)
print('MAE: ', -clf.best_score_)
# rank_test_score: 테스트 순위
# mean_score_time: 예측에 걸리는 시간
pd.DataFrame(clf.cv_results_).sort_values(by='rank_test_score').T
# 만들어진 모델에서 가장 성능이 좋은 모델을 불러옵니다.
pipe = clf.best_estimator_
from sklearn.metrics import mean_absolute_error
y_pred = pipe.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
print(f'테스트세트 MAE: ${mae:,.0f}')bestestimator 는 CV가 끝난 후 찾은 best parameter를 사용해
모든 학습데이터(all the training data)를 가지고 다시 학습(refit)한 상태
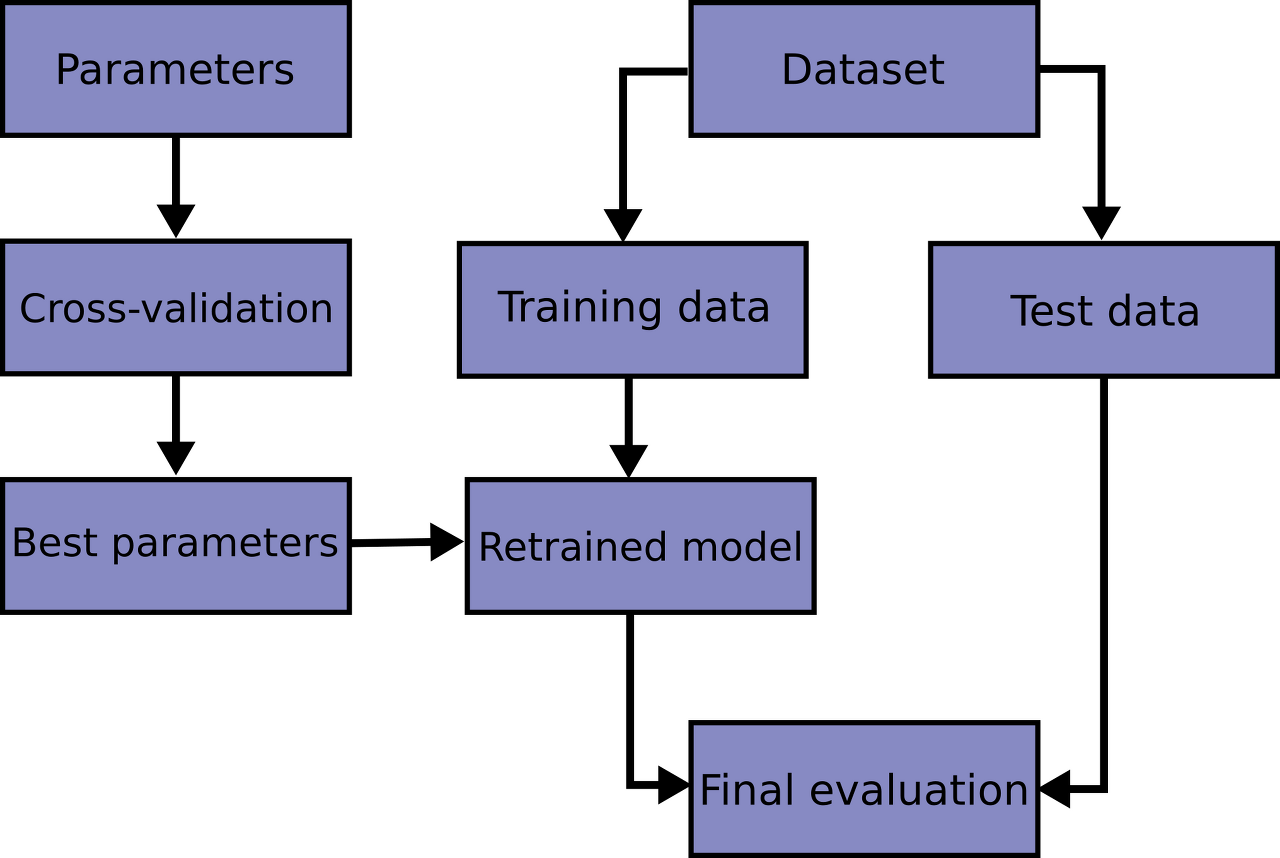
* hold-out 교차검증(훈련/검증/테스트 세트로 한 번만 나누어 실험)을 수행한 경우에는,
(훈련 + 검증) 데이터셋에서 최적화된 하이퍼파라미터로 최종 모델을 재학습(refit) 해야 합니다
선형회귀, 랜덤포레스트 모델들의 튜닝 추천 하이퍼파라미터 입니다
Random Forest
- class_weight (불균형(imbalanced) 클래스인 경우)
- max_depth (너무 깊어지면 과적합)
- n_estimators (적을경우 과소적합, 높을경우 긴 학습시간)
- min_samples_leaf (과적합일경우 높임)
- max_features (줄일 수록 다양한 트리생성)
Logistic Regression
- C (Inverse of regularization strength)
- class_weight (불균형 클래스인 경우)
- penalty
Ridge / Lasso Regression
- alpha
'Data Analysis, DA > Tree based Model' 카테고리의 다른 글
| n223 Evaluation Metrics for Classification (0) | 2021.06.19 |
|---|---|
| n222 RandomForest/ OrdinalEncoder (0) | 2021.06.19 |
| n221 Decision Trees, gini, entropy (0) | 2021.06.19 |



댓글