- 특성 중요도 계산 방법들(permutation importances, Feature importance, ...)을 이해하고 사용하여 모델을 해석하고 특성 선택시 활용할 수 있다.
- gradient boosting 을 이해하고 xgboost를 사용하여 모델을 만들 수 있다.
*특성 중요도( Feature Importances )
보통 가지에서 몇번 등장하는지, 혹은 불순도를 얼마나 낮추는 지에 대한 지표
기본 특성 중요도는 빠르지만 특성 종류에 따라 부정확한 결과가 나올 수 있어 주의가 필요합니다.
= 트리 모델에서 feature_importances_를 사용하면 cardinality가 높은 특성은 분기에 이용될 확률이
높아 중요도가 높게 나오는데, 따라서 모델이 과적합될 위험
and 문제점은 (-)영향을 주는 feature를 알수 없다는 것
순열 중요도 사용하면 더욱 정확한 계산이 가능합니다.
==> High Cardinality 경우 중요도가 높게 나옴
* 순열 중요도( Permutation Importances , Mean Decrease Accuarcy, MDA )
- 각 특성의 값을 랜덤하게 변형을 하고, 그때 얼마나 에러가 커지는 지를 기준으로 각 특성의 중요도 산출
( = 특성이 긍정인지 부정인지 알수는 없음)
==> 회귀경우 회귀계수로 파악할 수 있지만 분류모델의 경우는 해석이 어려움 so, PDP, SHAP 사용
= 특성 중요도와 Drop-column중요도의 중간에 위치하는 특징
= 중요도 측정은 관심있는 특성에만 무작위로 노이즈를 주고 예측을 하였을 때 성능 평가지표(정확도, F1,
r2 등)가 얼마나 감소하는지를 측정
*노이즈를 주는 가장 간단한 방법이 그 특성값들을 샘플들 내에서 섞는 것(shuffle, permutation)
직접 계산하는 건 번잡== eli5 사용
Feature importances - Tree-based or Boosting 계열 알고리즘에서 Feature별 중요도를 계산
Permutation imortance - 특정 입력 변수를 Shuffle 하고 예측력을 테스트해서 Shuffle 하기 전/후 예측력의 차이가 많이 나면 그만큼 중요하다고 판단
from sklearn.pipeline import Pipeline
# encoder, imputer를 preprocessing으로 묶었습니다. 후에 eli5 permutation 계산에 사용합니다
pipe = Pipeline([
('preprocessing', make_pipeline(OrdinalEncoder(), SimpleImputer())),
('rf', RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1))
])
pipe.fit(X_train, y_train)
print('검증 정확도: ', pipe.score(X_val, y_val))
import eli5
from eli5.sklearn import PermutationImportance
# permuter 정의
permuter = PermutationImportance(
pipe.named_steps['rf'], # model
scoring='accuracy', # metric
n_iter=5, # 다른 random seed를 사용하여 5번 반복
random_state=2
)
# permuter 계산은 preprocessing 된 X_val을 사용합니다.
X_val_transformed = pipe.named_steps['preprocessing'].transform(X_val)
# 실제로 fit 의미보다는 스코어를 다시 계산하는 작업입니다
permuter.fit(X_val_transformed, y_val);
feature_names = X_val.columns.tolist()
pd.Series(permuter.feature_importances_, feature_names).sort_values()
# 특성별 score 확인
eli5.show_weights(
permuter,
top=None, # top n 지정 가능, None 일 경우 모든 특성
feature_names=feature_names # list 형식으로 넣어야 합니다
)중요도가 -인 특성을 제외해도 성능은 거의 영향이 없으며, 모델학습 속도는 개선됩니다
* bagging(= 과적합을 해결하는 것이 주목적)
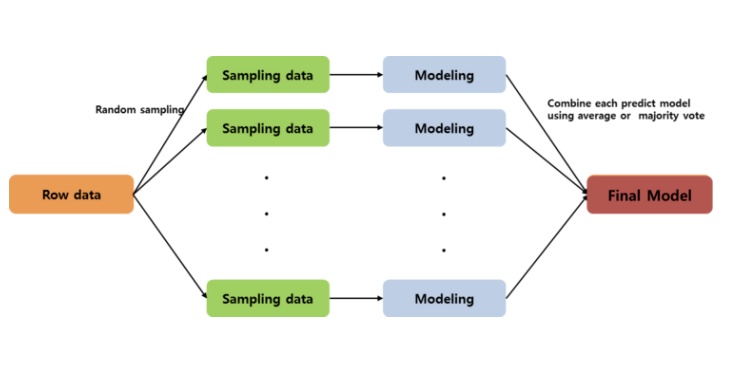
*boosting(= 정확도를 높이기 위한 주목적)
Gradient Boost는 single leaf부터 시작하며, 그 single leaf 모델이 예측하는 타겟 추정 값은 모든 타겟 값의 평균 single leaf에서 예측한 값과 실제 값의 차이(error)를 반영한 새로운 트리를 만들어야 합니다
https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-15-Gradient-Boost
머신러닝 - 15. 그레디언트 부스트(Gradient Boost)
앙상블 방법론에는 부스팅과 배깅이 있습니다. (머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)) 배깅의 대표적인 모델은 랜덤 포레스트가 있고, 부스팅의 대표적인 모
bkshin.tistory.com
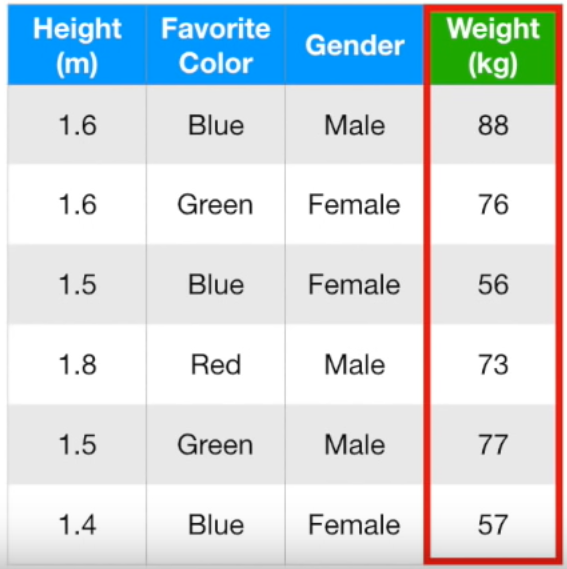
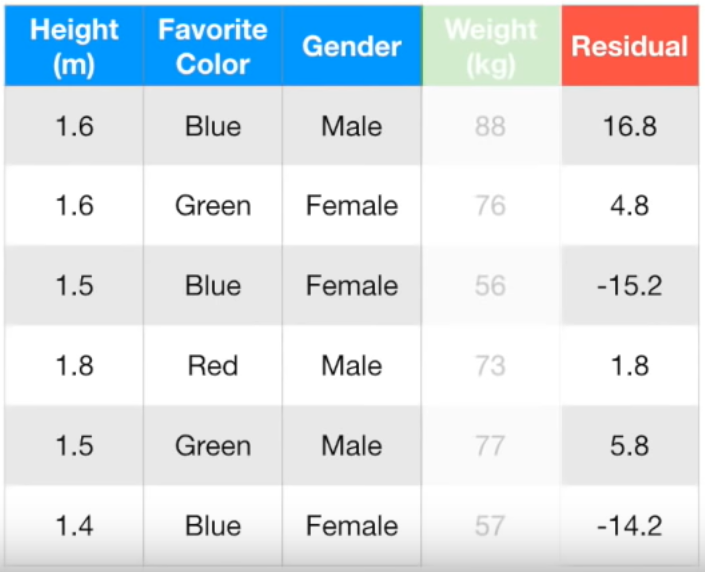
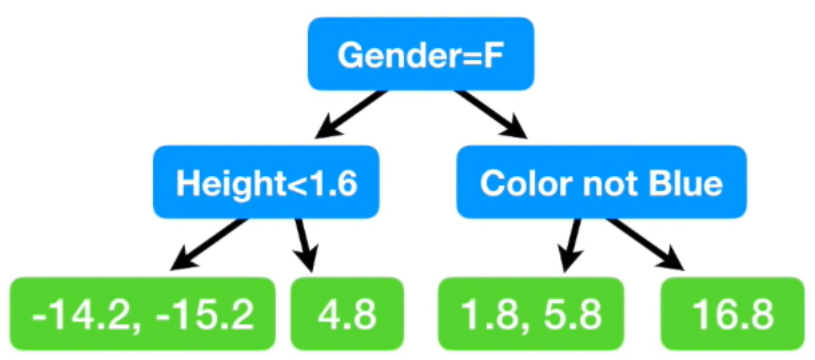
맨 처음 노드에선 성별이 여자면 왼쪽, 남자면 오른쪽
두번째 노드에선 각각 키가 1.6m 미만이면 왼쪽, 이상이면 오른쪽
좋아하는 색깔이 파란색이 아니면 왼쪽, 맞으면 오른쪽
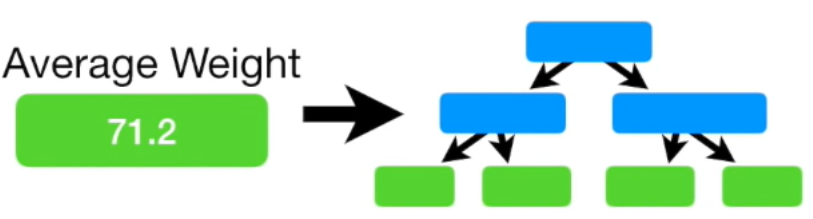
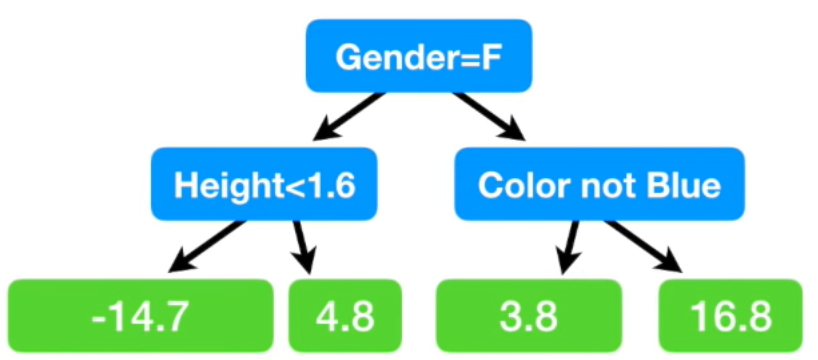
여기서 마지막 leaf 노드에 두개의 residual 값이 있는 경우가 있습니다. 그럴 땐 두 값의 평균으로 치환
(= {(-14.2) + (-15.2)} / 2 = -14.7이므로 -14.7)
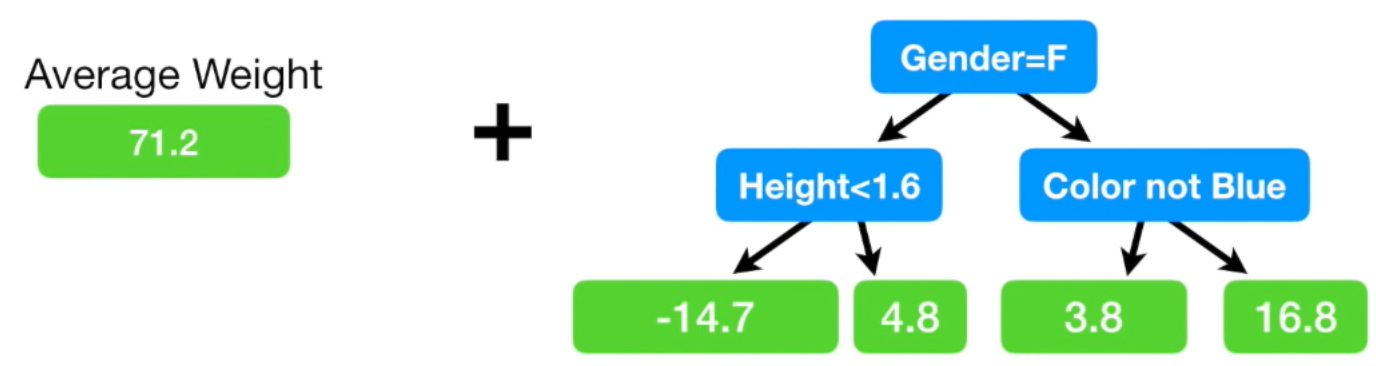
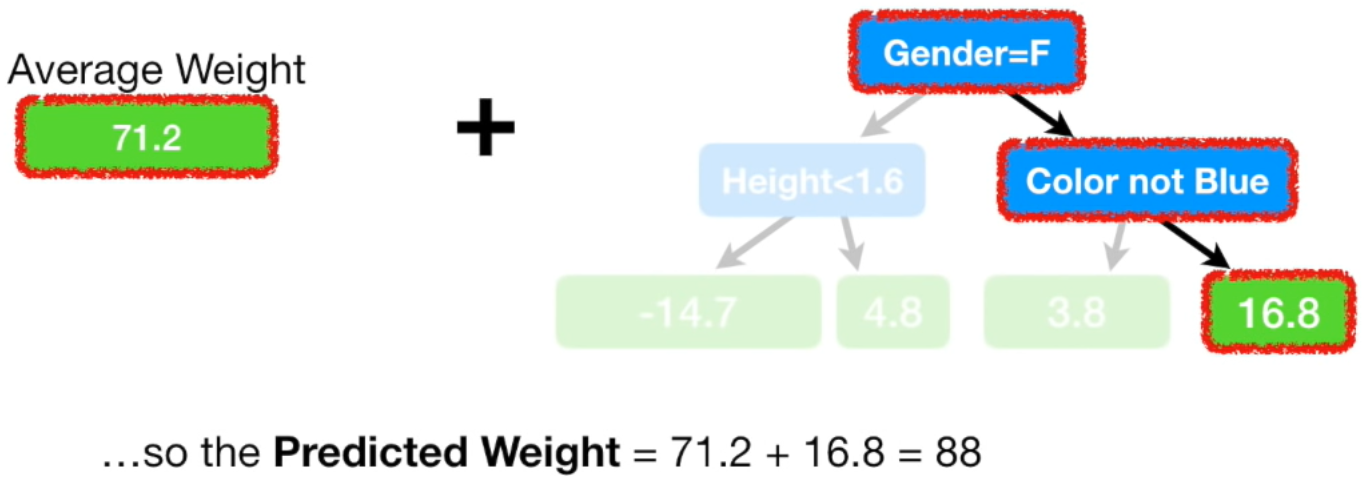
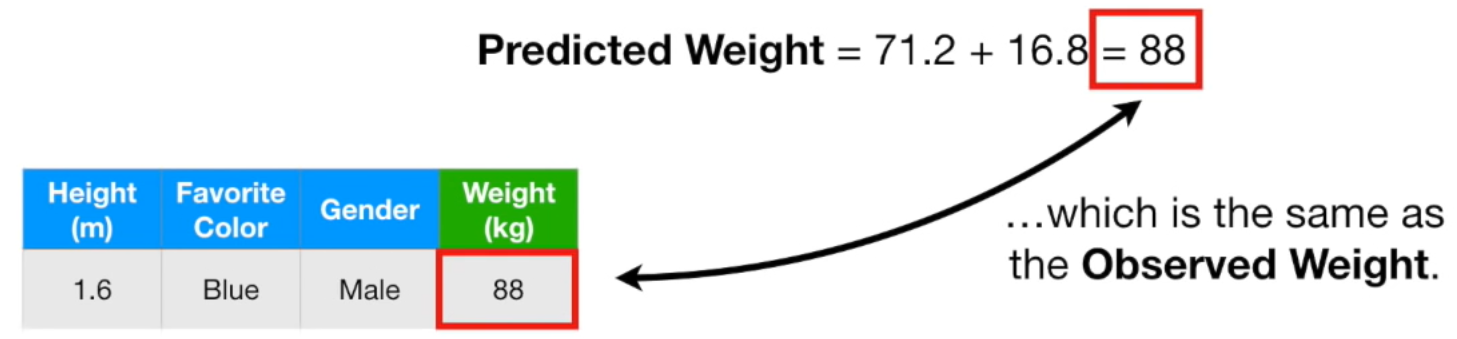
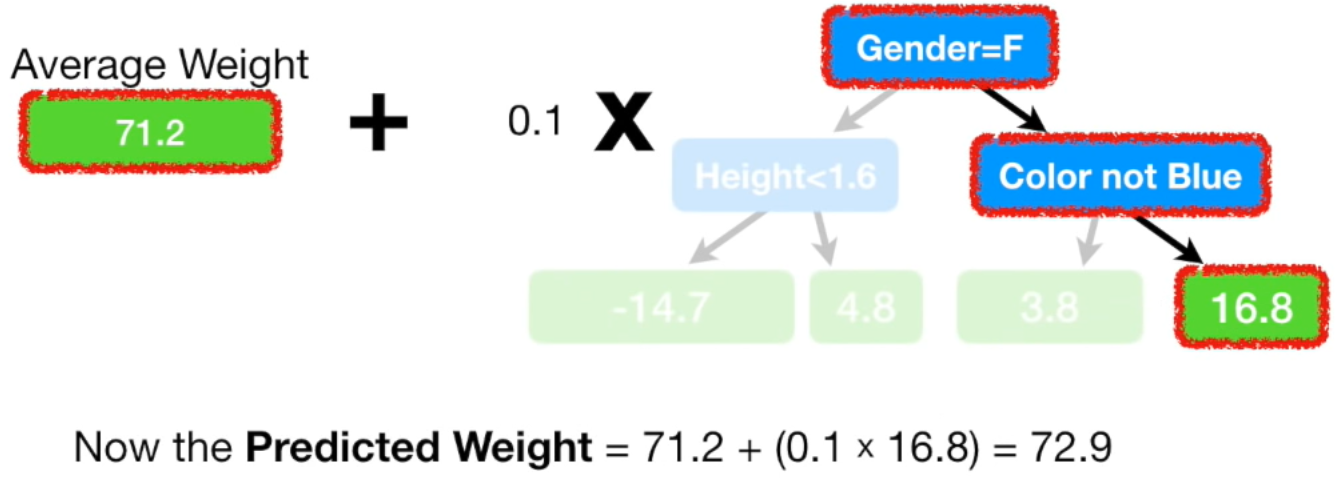
Gradient Boost 모델은 이런식으로 실제 값에 조금씩 가까워지는 방향으로 학습
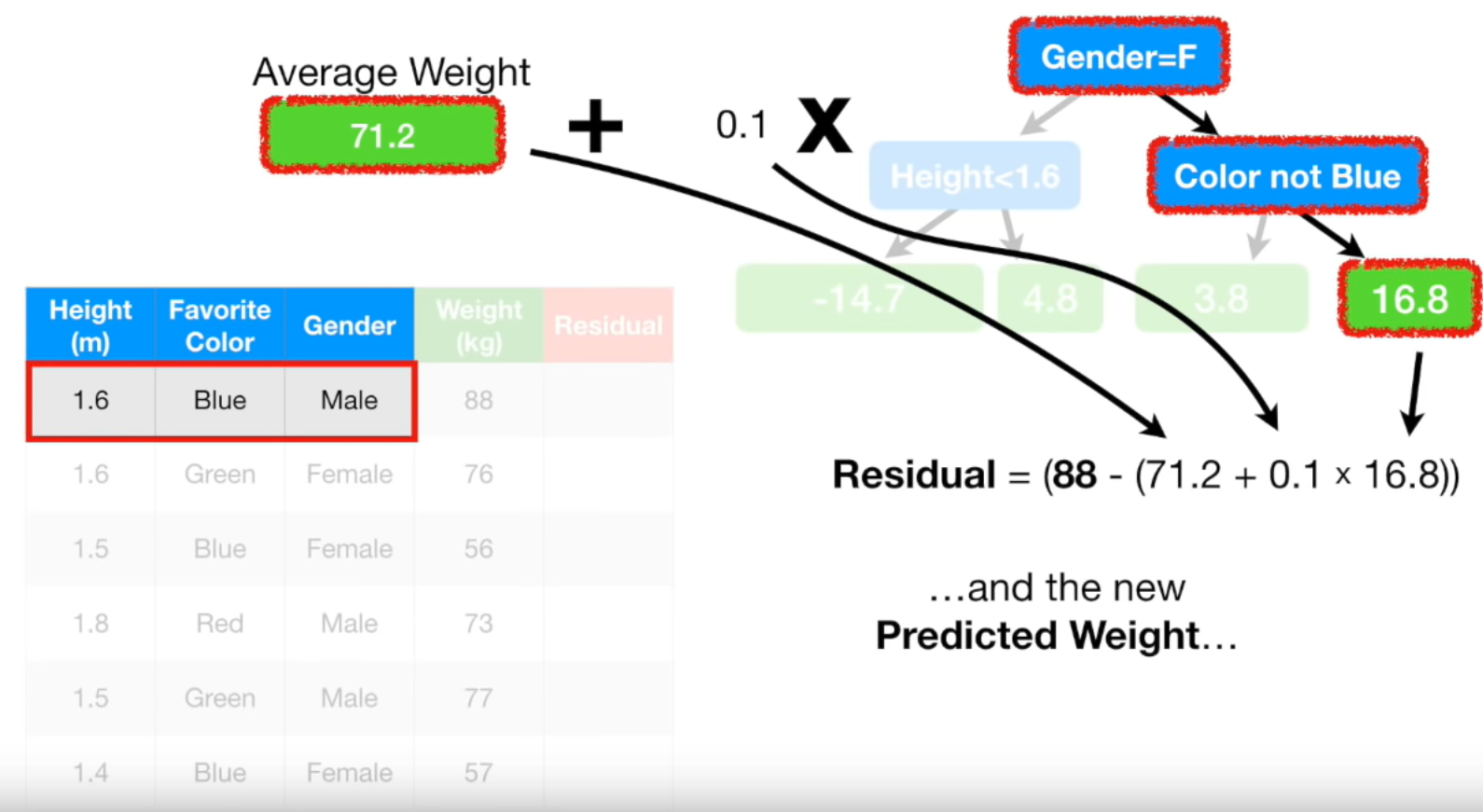
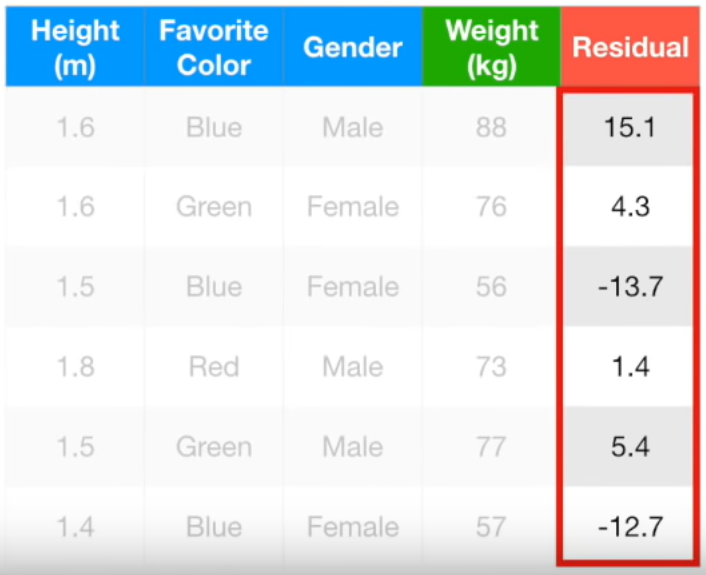
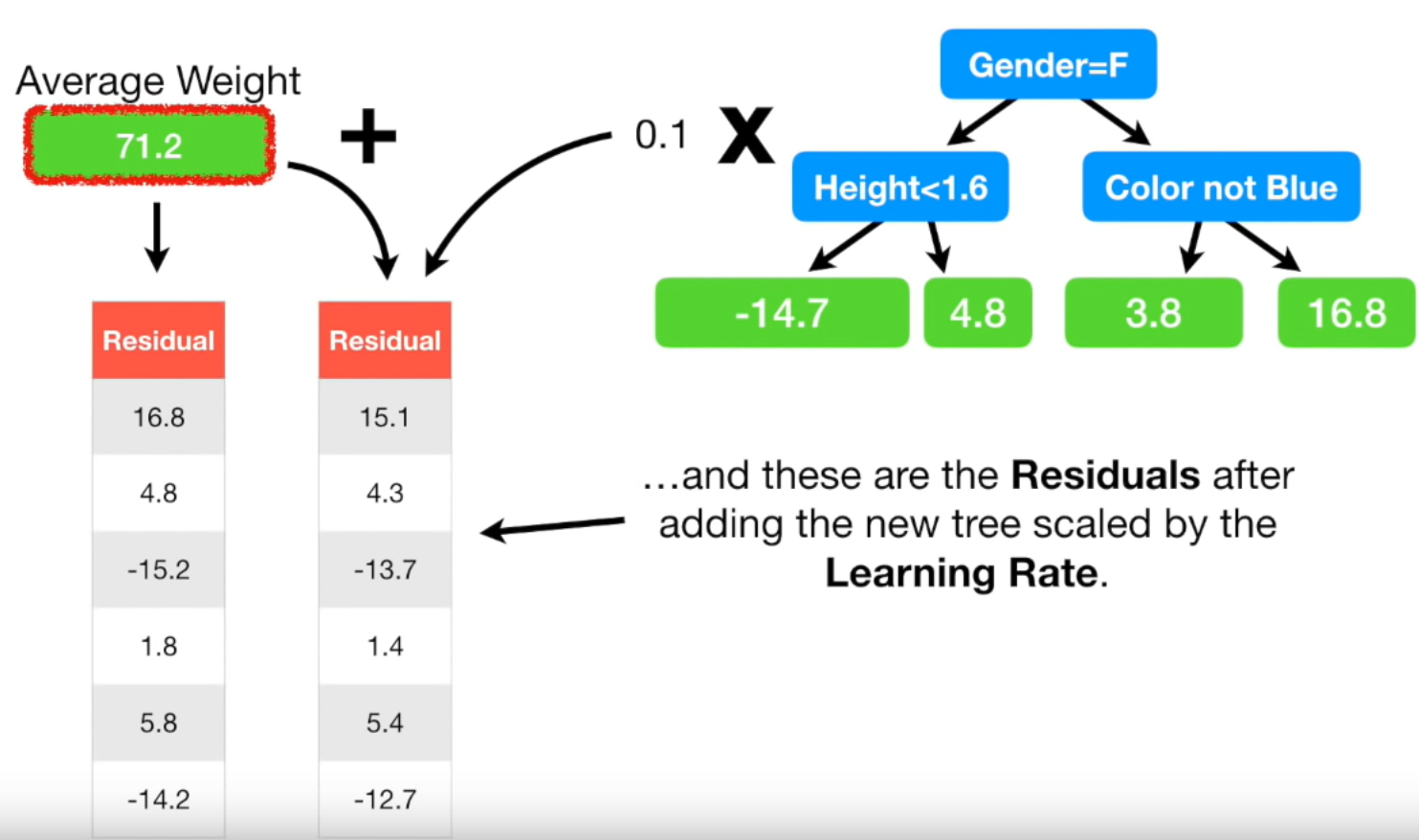
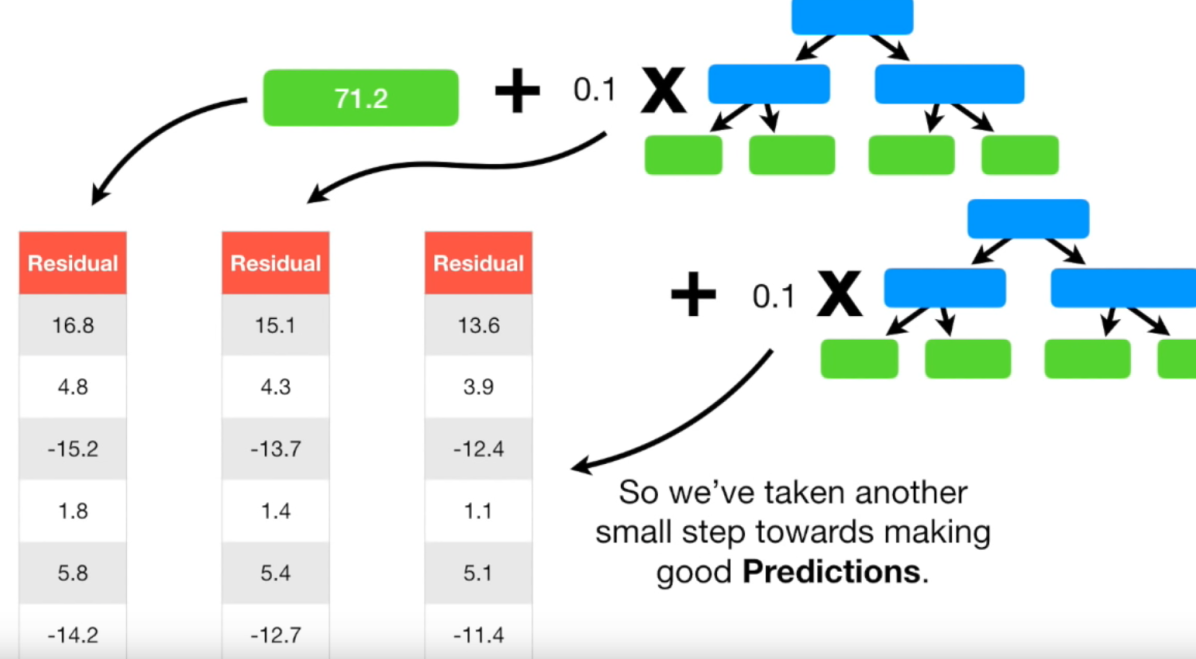
새로운 Residual은 초기 Residual보다 모두 작은 값입니다. Resiudal이 작아졌다는
뜻은 다른 말로 하면 실제 값과 예측 값의 차이가 작아졌다는 뜻입니다.
즉, 조금씩 실제 값으로 다가가고 있다는 뜻입니다.
== 이렇게 계속 반복합니다.
언제까지? 사전에 하이퍼 파라미터로 정해 놓은 iteration 횟수에 도달하거나 더 이상 residual이
작아지지 않을 때까지 반복
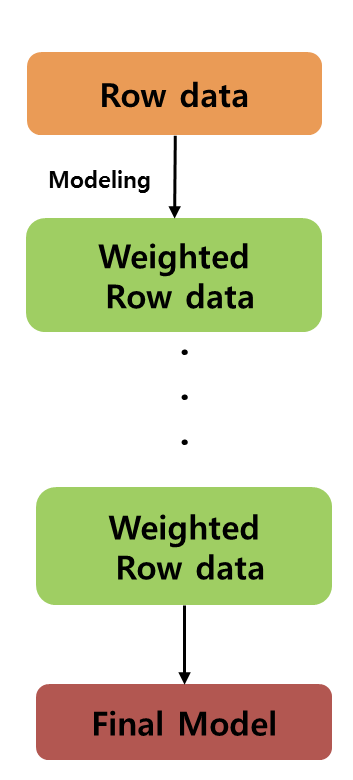
1 처음의 객체들에는 동일한 가중치
2. 모델링을 통한 예측변수의 의해 오분류된 객체들에는 높은 가중치 부여/
정분류된 객체들에는 낮은 가중치를 부여
==> 오분류된 객체들이 더 잘 분류되도록, 즉 예측모형의 정확도를 향상시키기위해 진행
*배깅
각각의 tree가 독립
*부스팅
오차를 보완해가며 약한모델은 가중치를 곱해주고
잘 분류된 모델은 가중치를 낮춰서 분류 진행
- 트리 앙상블은 랜덤포레스트나 그래디언트 부스팅 모델을 이야기 하며 여러 문제에서 좋은 성능을 보이는 것을 확인하였습니다.
- 트리모델은 non-linear, non-monotonic 관계, 특성간 상호작용이 존재하는 데이터 학습에 적용하기 좋습니다.
- 한 트리를 깊게 학습시키면 과적합을 일으키기 쉽기 때문에. 배깅(Bagging, 랜덤포레스트)이나 부스팅(Boosting) 앙상블 모델을 사용해 과적합을 피합니다.
- 랜덤포레스트의 장점은 하이퍼파라미터에 상대적으로 덜 민감한 것
- 그래디언트 부스팅의 경우 하이퍼파라미터 셋팅에 따라 랜덤포레스트 보다 더 좋은 예측 성능을 보여줄 수도 있습니다.
*배깅 속도빠름 = 병렬적으로 적합
*부스팅 속드느림 = 순차적으로 학습
==> 느린걸 보완 해주는 알고리즘이
XGboost, LGBM, catboost
(XGboost, catboost)level-wise 트리 분석은 균형을 잡아주어야 하기 때문에 tree의 depth가 줄어듬
그 대신 그 균형을 잡아주기 위한 연산이 추가되는 것이 단점
lightgbm은 트리의 균형은 맞추지 않고 리프 노드를 지속적으로 분할하면서 진행
그리고 이 리프 노드를 max delta loss 값을 가지는 리프 노드를 계속 분할해감
그렇기 때문에 비대칭적이고 깊은 트리가 생성되지만 동일한 leaf를 생성할 때
leaf-wise는 level-wise보다 손실을 줄일 수 있다는 것이 장점
출처: https://lsjsj92.tistory.com/548 [꿈 많은 사람의 이야기]
- scikit-learn Gradient Tree Boosting — 상대적으로 속도가 느릴 수 있습니다.
- Anaconda: already installed
- Google Colab: already installed # sklearn에서 잘 안쓰임
- xgboost — 결측값을 수용하며, monotonic constraints를 강제할 수 있습니다.
- Anaconda, Mac/Linux: conda install -c conda-forge xgboost
- Windows: conda install -c anaconda py-xgboost
- Google Colab: already installed
- LightGBM — 결측값을 수용하며, monotonic constraints를 강제할 수 있습니다.
- Anaconda: conda install -c conda-forge lightgbm
- Google Colab: already installed
- Neural Networks나 LightGBM과 같은 몇몇 모델의 경우, predict 메서드는 예측된 클래스 레이블이 아니라 각 클래스에 대한 출력 확률(probability)을 반환
## (n_samples, n_classes) 모양의 NumPy 배열이라면
y_test_pred = np.argmax(y_test_pred, axis=1)- CatBoost — 결측값을 수용하며, categorical features를 전처리 없이 사용할 수 있습니다.
- Anaconda: conda install -c conda-forge catboost
- Google Colab: pip install catboost
- ==> 기본적으로 TargetEncoding 시행, low cardinalit 경우 OneHotEncoding 시행
- 대부분 범주형형일 때 사용하면 탁월
*Early stopping
GrideSearchCV 나 반복문 같은경우는 해당 파라미터 값에 따라 돌려야하기 때문에 시간이 오래걸림
Early stopping이 효과적
# 클래스의 비율
y_train.value_counts(normalize=True)
ratio = 0.15/0.84
ratio
'''
# Pipeline 만들어서 하는 경우
processor = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='median')
)
X_train_processed = processor.fit_transform(X_train)
X_val_processed = processor.transform(X_val)
'''
encoder = OrdinalEncoder()
X_train_encoded = encoder.fit_transform(X_train) # 학습데이터
X_val_encoded = encoder.transform(X_val) # 검증데이터
model = XGBClassifier(
n_estimators=1000, # <= 1000 트리로 설정했지만, early stopping 에 따라 조절됩니다.
max_depth=7, # default=3, high cardinality 특성을 위해 기본보다 높여 보았습니다.
learning_rate=0.2,
# scale_pos_weight=ratio, # imbalance 데이터 일 경우 비율을 적용합니다.
n_jobs=-1
)
eval_set = [(X_train_encoded, y_train),
(X_val_encoded, y_val)]
model.fit(X_train_encoded, y_train,
eval_set=eval_set,
eval_metric='error', # #(wrong cases)/#(all cases)
early_stopping_rounds=50
) # 50 rounds 동안 스코어의 개선이 없으면 멈춤
##########test
X_test_processed = processor.transform(X_test)
X_val_processed = processor.transform(X_val)
class_index = 1
y_pred_proba = model.predict_proba(X_test_processed)[:, class_index]
print(f'Test AUC for class "{model.classes_[class_index]}":')
print(roc_auc_score(y_test, y_pred_proba))
# Confution matrix
y_test_pred = model.predict(X_test_processed)
print(classification_report(y_test, y_test_pred))n_estimators ==> 너무 크게주면 긴 학습시간, early_stopping_rounds 같이 사용
* XGboost 과적합 제어 하이퍼파라미터
- 첫 번째 방법은 모델 복잡성을 직접 제어하는 것입니다.
- 여기에는 max_depth, min_child_weight하고 gamma.
- 두 번째 방법은 무작위성을 추가하여 학습을 노이즈에 견고하게 만드는 것입니다.
- 여기에는 subsample및 colsample_bytree.
- stepize를 줄일 수도 있습니다 eta. num_round그렇게 할 때 증가하는 것을 잊지 마십시오.
* XGboost 불균형 데이터 셋 처리
- 예측의 전체 성능 지표 (AUC)에만 관심이있는 경우
- 다음을 통해 긍정적 인 가중치와 부정적인 가중치의 균형을 scale_pos_weight
- 평가를 위해 AUC 사용
- 올바른 확률을 예측하는 데 관심이 있다면
- 이 경우 데이터 세트를 재조정 할 수 없습니다.
- max_delta_step수렴을 돕기 위해 매개 변수 를 유한 수 (예 : 1)로 설정합니다.
* process
1. 먼저 RandomForest 학습
- 어느정도 성과를 낼 수 있는지 가늠
2. 실제 모델은 Gradient Boosting으로 최적화 ==> 정확도 높이기 위해
하이퍼파라미터 튜닝
Random Forest
- max_depth (높은값에서 감소시키며 튜닝, 너무 깊어지면 과적합)
- n_estimators (적을경우 과소적합, 높을경우 긴 학습시간)
- min_samples_leaf (과적합일경우 높임)
- max_features (줄일 수록 다양한 트리생성, 높이면 같은 특성을 사용하는 트리가 많아져 다양성이 감소)
- class_weight (imbalanced 클래스인 경우 시도)
XGBoost
- learning_rate (높을경우 과적합 위험이 있습니다)
- max_depth (낮은값에서 증가시키며 튜닝, 너무 깊어지면 과적합위험, -1 설정시 제한 없이 분기, 특성이 많을 수록 깊게 설정)
- n_estimators (너무 크게 주면 긴 학습시간, early_stopping_rounds와 같이 사용)
- scale_pos_weight (imbalanced 문제인 경우 적용시도)
과적합일 경우
- eta(learning_rate) 값을 낮춘다. (0.01~0.1) 그리고 eta(learning_rate)값을 낮추는 경우 num_boost_rounds(n_estimators) 는 반대로 높여준다.
- max_depth 값을 낮춘다.
- min_child_weight 값을 높인다.
- gamma 값을 높인다.
- sub_sample(subsample), colsample_bytree 를 조정해서 트리가 복잡해지는 것을 막는다.
'Data Analysis, DA > Interpreting Model' 카테고리의 다른 글
| n234 Interpreting ML Model( X-AI ) (0) | 2021.06.26 |
|---|---|
| n232 Data Wrangling(랭글링) / merge / groupby (0) | 2021.06.26 |
| n231 Choose your ML problems (0) | 2021.06.26 |



댓글