Generalization :
통계에서 말하는 일반화를 말한다. 기계학습에서는 일반화 성능을 향상시킨다는 말이 많이 나오는데,
Train data에 너무 overfitting 되지 않고, 좀 더 일반적인 모델을 만드는 것을 의미한다
== 학습된 모델이 새로운 데이터에서 얼마나 좋은 실행이 일어나는지의 정도
출처: https://jkook.tistory.com/23 [JinKook]
Normalization

- 값의 범위(scale)를 0~1 사이의 값으로 바꾸는 것
- 학습 전에 scaling하는 것
- 머신러닝에서 scale이 큰 feature의 영향이 비대해지는 것을 방지
- 딥러닝에서 Local Minima에 빠질 위험 감소(학습 속도 향상)
==> normalization 하지 않으면 중요한 특성임에도 다른 특성에 가중치를 주게됨
피처의 스케일이 심하게 차이가 나는 경우 값이 큰 피처가 더 중요하게 여겨질 수 있기 때문
* 사용되는 특성(feature)들이 모두 비슷한 영향력을 행사하도록 값을 변환해주는 기술

한 특성 내에 가장 큰 값은 1로, 가장 작은 값은 0으로 변환되고
각 특성들의 값을 변환해주면 모두 [0, 1]의 범위를 갖게됨(= 특성들이 평등한 위치 )
== 최소값은 0, 최댓값은 1이 되고, 나머지 값들은 그 사이로 정규화
* Sclaer 종류
1. StandardScaler() - 기본 스케일, 평균과 표준편차 사용 - 표준화
2. MinMaxScaler() - 최대/최소값 각각 1, 0이 되도록 스켈일링 - 정규화
3. MaxAbsScaler() - 최대절대값과 0이 각각 1, 0이 되도록 스케일링 - 정규화
4. RobustScaler() - 중앙값(median)과 IQR(Interquartile range) 사용 = outlier 영향 최소화 - 표준화
1. StandardScaler
평균을 제거하고 데이터를 단위 분산으로 조정한다. 그러나 이상치가 있다면 평균과 표준편차에
영향을 미쳐 변환된 데이터의 확산은 매우 달라지게 된다.
따라서 이상치가 있는 경우 균형 잡힌 척도를 보장할 수 없다.
2. MinMaxScaler
모든 feature 값이 0~1사이에 있도록 데이터를 재조정한다. 다만 이상치가 있는 경우 변환된 값이
매우 좁은 범위로 압축될 수 있다.
즉, MinMaxScaler 역시 아웃라이어의 존재에 매우 민감하다.
3. MaxAbsScaler
절대값이 0~1사이에 매핑되도록 한다. 즉 -1~1 사이로 재조정한다. 양수 데이터로만 구성된 특징 데이터셋에서는 MinMaxScaler와 유사하게 동작하며, 큰 이상치에 민감할 수 있다.
4. RobustScaler
아웃라이어의 영향을 최소화한 기법이다. 중앙값(median)과 IQR(interquartile range)을 사용하기 때문에 StandardScaler와 비교해보면 표준화 후 동일한 값을 더 넓게 분포 시키고 있음을 확인 할 수 있다.

| train_data | MinMaxScaler | MaxAbsScaler | StandardScaler | RobustScaler |
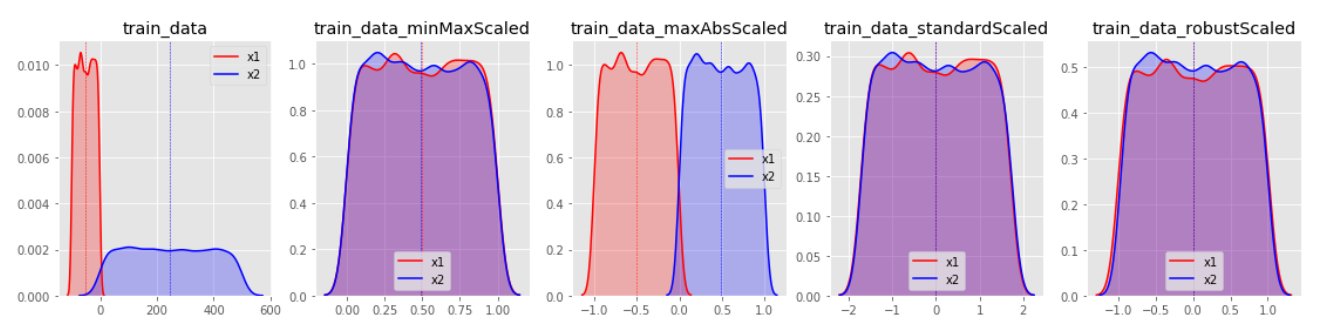

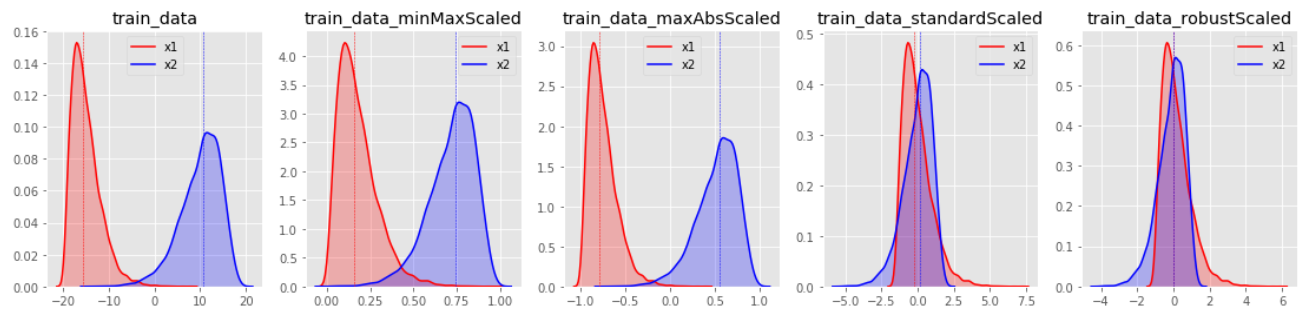

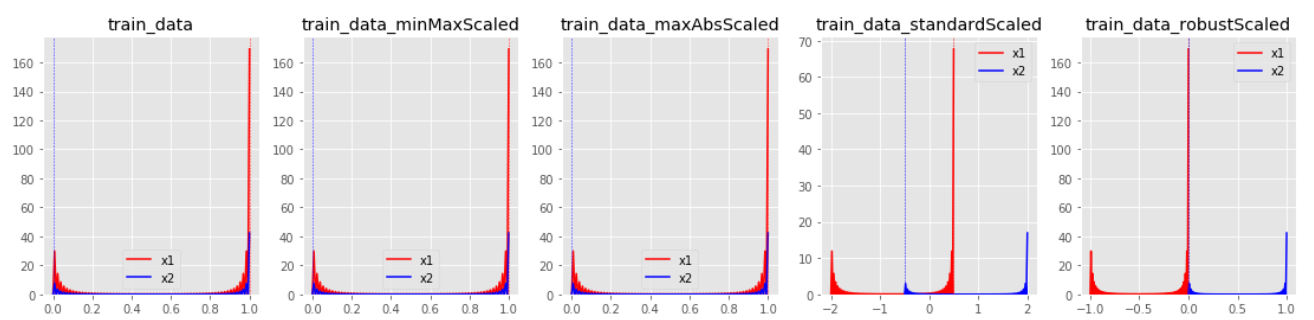
* StandardScaler와 RobustScaler의 변환된 결과가 대부분 표준화된 유사 형태의 데이터 분포로 반환된다.
* MinMaxScaler 한쪽으로 쏠림 현상이 있는 데이터 분포는 형태가 거의 유지된채 범위값이 조절되는 결과를 보인다.
참조 https://mkjjo.github.io/python/2019/01/10/scaler.html
[Python] 어떤 스케일러를 쓸 것인가?
* 본 포스트는 개인연구/학습 기록 용도로 작성되고 있습니다. By MK on January 10, 2019 데이터를 모델링하기 전에는 반드시 스케일링 과정을 거쳐야 한다. 스케일링을 통해 다차원의 값들을 비교 분
mkjjo.github.io
* Batch Normaliztion


Batch Normalization을 사용하는 이유는,
1. 학습 속도 상승
2. 초기 파라미터 의존도 약화
3. 모델 성능 향상
예를들면 키와 나이로 이루어진 데이터를 사용하여 분석한다 했을 때,
age는 범위가 0~100정도이고, 키는 미터법으로 했을 때 0~2정도입니다.
평균적으로 관측으로 나타나는 값 역시 서로 다르니 이를 분석하려면 매우 협소한 기준을 가지고 봐야한다.(그림1)
(실제로 두 데이터 축을 두고 그래프를 그려보면 분포가 매우 가늘고 일그러짐을 알수 있습니다.)
하지만 Normalization을 통해 이 둘의 스케일을 맞춰준다(그림2)= (x - 평균) / 표준편차
1,3. 같은 결과에 영향을 주는 서로 다른 두 데이터 특징의 사이즈가 서로 통일되면, 학습 방향에 따라 보다
안정적이고 빠르게 학습이 진행되기에 학습 속도가 상승
2. 스케일이 서로 다르고, 한쪽 스케일만 엄청나게 크다면, 파라미터에 대해 서로 영향을 받게되므로
이 경우 초기 파라미터가 만약 파라미터 골짜기의 이상한 곳에 위치한다면 그것을 빠져나오기 힘들 것이고,
고로 이 경우엔 기울기 소실 문제도 Normalization이 해결해준다는 것
Standardization
- Feature가 정규분포인 경우 유용
- 종모양의 분포를 따른다고 가정하고 값들을 0의 평균, 1의 표준편차를 갖도록 변환 (= 졍규분포의 표준화 )

표준화는 어떤 특성의 값들이 정규분포, 즉 종모양의 분포를 따른다고
가정하고 값들을 0의 평균, 1의 표준편차를 갖도록 변환해주는 것
== 정규분포의 표준화공식

- 값의 범위(scale)를 평균 0, 분산 1이 되도록 변환, 학습 전에 scaling하는 것
- 머신러닝에서 scale이 큰 feature의 영향이 비대해지는 것을 방지
- 딥러닝에서 Local Minima에 빠질 위험 감소(학습 속도 향상)
==> 평균에 비해 최댓값이 너무 멀리있을 경우(= outlier )
outlier에 대해 올바른 결과를 내는 모델은 상황에 따라, 평균 근처의 값들(대부분의 값들)에
대한 결과를 올바르지 못 하게 낼 수도 있다.
머신러닝 모델의 학습을 방해하는 outlier들을 제외할 수 있다
학습 데이터 : fit() 과 transform() 사용
테스트 데이터 : transform() 만 사용
이런 주의사항이 발생하기 때문에 되도록 데이터를 분리하기 전에 스케일링을 적용하는 것이 좋습니다.
mm_scaler = StandardScaler()
cancer_data = cancer.data
cancer_target = cancer.target
scaled_cancer = mm_scaler.fit_transform(cancer_data)
X_train, X_test, y_train, y_test = train_test_split(scaled_cancer,
cancer.target,
test_size = 0.2,
stratify=cancer.target,
random_state=2)결론
모든 스케일러 처리 전에는 아웃라이어 제거가 선행되어야 한다.
또한 데이터의 분포 특징에 따라 적절한 스케일러를 적용해주는 것이 좋다.
표준화를 통해 이상치를 제거하고, 그 다음 데이터를 정규화 해 상대적 크기에 대한 영향력을 줄인 다음 분석을 시작한다
고 한다.
어떤 경우에는 정규화를 해줬을 때 더 좋은 성능을 낼 수 있고, 어떤 경우에는 표준화가 더 나을 수도 있다.
따라서 둘 다 해보고 어느 것이 더 나은지 비교해봐야함
때에 따라선 Standardization 이후에 Normalization을 추가로 하기도 한다.
Regularization
- weight를 조정하는데 규제(제약)를 거는 기법
- Overfitting을 막기위해 사용함(= 과적합을 완화해 일반화 성능을 높여주기 위한 기법)
- L1 regularization, L2 regularizaion 등의 종류가 있음
- L1: LASSO(라쏘), 마름모
- L2: Lidge(릿지), 원
- https://realblack0.github.io/

'IT 개인학습 > Memo' 카테고리의 다른 글
| Deploy (0) | 2022.05.07 |
|---|---|
| Jenkins 젠킨스 (0) | 2022.05.07 |
| SQL (0) | 2022.05.07 |
| Airflow (0) | 2022.05.07 |
| Train / Validation / Test (0) | 2021.07.07 |



댓글