전이학습 (Transfer Learning)
"기존(내 목적과는 다른) 데이터로 학습된 네트워크를 재사용 가능하도록하는 라이브러리"
- 사전에 대량의 data를 학습한 것을 불러와서 다른 목적으로 사용가능
==> 가중치, 편향이 포함된 학습된 모델의 일부를 재사용하기에 Transfer learning 이라고 표현
교육 데이터를 적게 사용하고, 교육 속도가 빠르며, 더 잘 일반화하는 모델을 가질 수 있다.
(일부만 사용을 해서 활용할 수 도 있지만, 전체를 다 재학습할 수도 있다)

1. 이전에 학습한 모델에서 파라미터를 포함한 레이어를 가져옵니다.
2. 향후 교육 과정 중에 포함된 정보가 손상되지 않도록 해당 정보를 동결(freeze, 가중치를 업데이트 하지 않음)합니다.
3. 동결된 층 위에 새로운 층 (학습 가능한 층)을 더합니다.
- 출력층(output)의 수를 조절하여 새로운 데이터셋에서 원하는 예측방법(분류, 회귀 등)으로 전환하는 방법을 배울 수 있게됩니다.
4. 새로운 데이터셋에서 새로 추가한 계층만을 학습합니다.
- 만약 기존 레이어를 동결하지 않으면, 학습된 레이어에서 가져온 weight까지 학습하게 됩니다.
- 위 경우 학습할 것이 많아지므로 시간이 오래걸립니다.
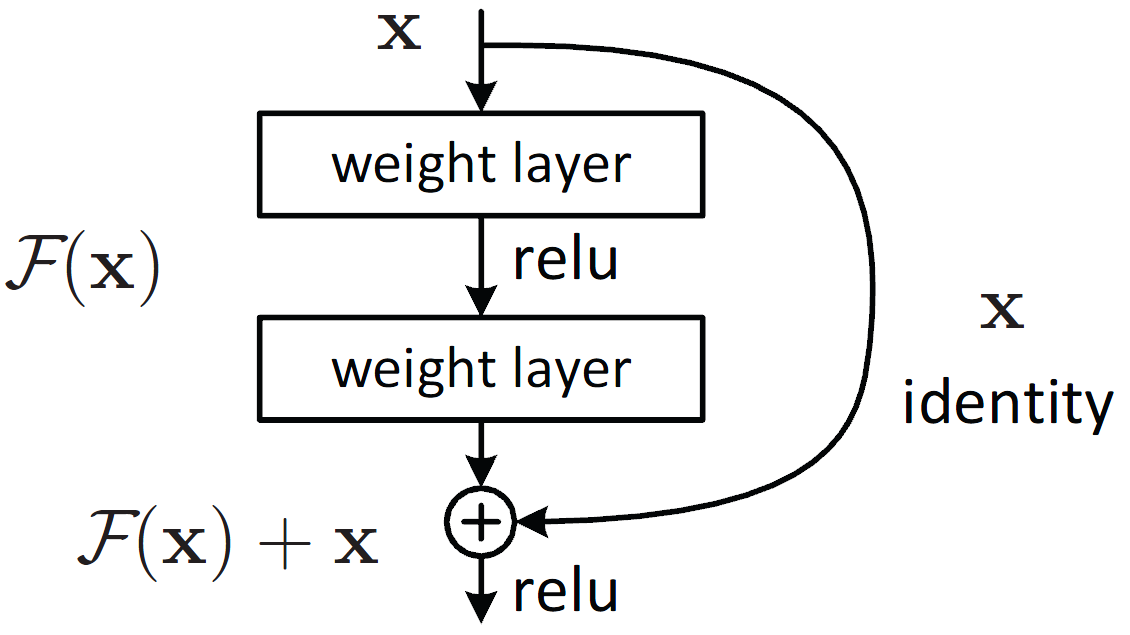
* Skipped connection
원래 것도 보존하면서 어떤 특징값이 반영된 형태의 이미지
convolution layer층을 지난다 하면 행렬곱으로 인한 값이 변형되고 또한 함수(ReLu)를
통해서 0보다 작은 값은 사라지게 되는데 이러한 연산이 몇 번 반복 될 수가 있다.
그러면서 원래의 이미지가 변형이 일어나는데 원래의 이미지를 추가함으로서
이러한 특징(이미지 변형)값이 반영된 이미지를 가져오게 된다.(특징 값이 강조된)
from keras.applications.resnet50 import ResNet50
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
# 모델 제작
model = Sequential()
# weights = resnet_weights_path 학습해둔 모델이 있으면 이렇게 불러올 수 있음
model.add(ResNet50(include_top = False, pooling = RESNET50_POOLING_AVERAGE))
# include_top=False 로 하면, 기존 1000가지 클래스로의 분류 문제를 풀 수 있는 ResNet 모델에서
# Fully Connected layer 부분을 제거해주는 역할
model.add(Dense(NUM_CLASSES, activation = DENSE_LAYER_ACTIVATION))
# 이미 학습된 영역은 학습하지 않겠다고 설정하는 옵션
model.layers[0].trainable = False
from tensorflow.keras import optimizers
# optimizer, compile
sgd = optimizers.SGD(lr = 0.01, decay = 1e-6, momentum = 0.9, nesterov = True)
model.compile(optimizer = sgd, loss = OBJECTIVE_FUNCTION, metrics = LOSS_METRICS)데이터 증강(Augmentation)
모델은 데이터의 양이 적을 경우, 해당 데이터의 특정 패턴이나 노이즈까지 쉽게 암기를 하게 되므로
과적합 현상이 발생할 확률이 늘어난다. 그렇기 때문에 데이터의 양을 늘릴 수록 모델은 데이터의
일반적인 패턴을 학습하여 과적합을 방지할 수 있다. 만약, 데이터의 양이 적을 경우에는의도적으로
기존의 데이터를 조금씩 변형하고 추가하여 데이터의 양을 늘리기도 하는데
이를 데이터 증식 또는 증강(Data Augmentation)
이미지의 경우에는 데이터 증식이 많이 사용되는데 이미지를 돌리거나 노이즈를 추가하고,
일부분을 수정하는 등으로 데이터를 증식시킨다.
(= 데이터를 추가적으로 얻기란 쉽지 않고 비용도 많이 든다고한다)
즉, 기본적인 이미지에서 여러방식으로 변조를 가한 데이터를 추가하여, 그것을 학습 데이터로
사용함으로써 학습과 검증의 오버피팅을 줄인다.
* using .flow(x, y)
# 모델 생성 후
from keras.applications.resnet50 import preprocess_input
from keras.preprocessing.image import ImageDataGenerator
# 입력 이미지 사이즈 정의
image_size = IMAGE_RESIZE
# 입력 이미지, 데이터 증량(Augmentation)
datagen = ImageDataGenerator(
preprocessing_function=preprocess_input,
featurewise_center=True,
featurewise_std_normalization=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
'''
* preprocessing=
function that will be applied on each input.
The function will run after the image is resized and augmented.
The function should take one argument: one image (Numpy tensor with rank 3),
and should output a Numpy tensor with the same shape.
* featurewise_center, featurewise_std_normalization=
정규화
* zca_whitening=
Boolean. Apply ZCA whitening.
'''
# compute quantities required for featurewise normalization
# (std, mean, and principal components if ZCA whitening is applied)
datagen.fit(train_images)
model.fit(datagen.flow(train_images, train_labels, batch_size=32),
esteps_per_epoch=len(train_images) / 32, epochs=NUM_EPOCHS)
'''
validation_data=datagen.flow(train_images, train_labels, batch_size=8,
subset='validation')), ## ???
'''* using .flow_from_directory(directory)
= train / validation data가 나눠진 폴더가 있을경우
STEP 1. ImageDataGenerator
original_datagen = ImageDataGenerator(rescale=1./255)
'''
rescale: 이미지의 픽셀 값을 조정
rotation_range: 이미지 회전
width_shift_range: 가로 방향으로 이동
height_shift_range: 세로 방향으로 이동
shear_range: 이미지 굴절
zoom_range: 이미지 확대
horizontal_flip: 횡 방향으로 이미지 반전
fill_mode: 이미지를 이동이나 굴절시켰을 때 빈 픽셀 값에 대하여 값을 채우는 방식
'''rescale:
transformation은 이미지에 변화를 주어서 학습 데이터를 많게 해서 성능을 높이기 위해 하는 것이기
때문에 train set만 해주고, test set에는 해 줄 필요가 없다. 그러나 주의할 것은 Rescale은 train, test
모두 해 주어야 한다.
STEP 2. Make Generator
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = utils.to_categorical(y_train, num_classes)
y_test = utils.to_categorical(y_test, num_classes)
# train
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# test
test_datagen = ImageDataGenerator(rescale=1./255)
# flow_from_directory
'''
Takes the path to a directory & generates batches of augmented data
'''
train_generator = train_datagen.flow_from_directory(
'data/train', # string, path to the target directory.
target_size=(150, 150), # defaults to (256,256)
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
'data/validation',
target_size=(150, 150),
batch_size=32,
class_mode='binary')
# model fit
model.fit(
train_generator,
steps_per_epoch=2000,
epochs=50,
validation_data=validation_generator,
validation_steps=800)ImageDataGenerator.flow_from_directory(
directory,
target_size=(256, 256), # 정수 튜플 (height, width), 기본값은 (256, 256)
color_mode="rgb",
classes=None,
class_mode="categorical", # "categorical", "binary", "sparse", "input" 또는 None 중 하나
batch_size=32,
shuffle=True,
seed=None,
save_to_dir=None,
save_prefix="",
save_format="png",
follow_links=False,
subset=None,
interpolation="nearest",
)이미지 데이터 불러오는 방법
Keras documentation: Image data preprocessing
Image data preprocessing image_dataset_from_directory function tf.keras.preprocessing.image_dataset_from_directory( directory, labels="inferred", label_mode="int", class_names=None, color_mode="rgb", batch_size=32, image_size=(256, 256), shuffle=True, seed
keras.io
import numpy as np
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D, Conv2D, MaxPooling2D, Flatten
from tensorflow.keras.models import Model
resnet = ResNet50(weights='imagenet', include_top=False)
'''
include_top=False 로 하면,
기존 1000가지 클래스로의 분류 문제를 풀 수 있는 ResNet 모델에서
Fully Connected layer 부분을 제거해주는 역할
'''
# ResNet50 레이어들의 파라미터를 학습하지 않도록 설정
for layer in resnet.layers:
layer.trainable = False
# 모델에 추가로 Fully-conneted layer(Dense) 를 추가해야된다.
# 사전 학습 모델을 불러오면서 최상위 레이어인 Fully-conneted layer 를 제거했기 때문에
x = resnet.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(1, activation='sigmoid')(x) # 출력층을 설계합니다.
model = Model(resnet.input, predictions)
model.summary()
# 모델 compile 후
train = tf.keras.preprocessing.image_dataset_from_directory(
'/content/drive/Othercomputers/내 노트북/Desktop/AI Bootcamp/SECTION4/sprint3/mountainForest/train',
labels='inferred',
label_mode='int',
class_names={'forest':0, 'mountain':1},
image_size=(128, 128),
batch_size=32)
val = tf.keras.preprocessing.image_dataset_from_directory(
'/content/drive/Othercomputers/내 노트북/Desktop/AI Bootcamp/SECTION4/sprint3/mountainForest/validation',
labels='inferred',
label_mode='int',
class_names={'forest':0, 'mountain':1},
image_size=(128, 128),
batch_size=32)
model.fit(train, batch_size=64, epochs=5, validation_data=(val))
model.evaluate(val)
##################################################################################
tf.keras.preprocessing.image_dataset_from_directory(
directory,
labels="inferred", # 레이블은 이미지 파일 경로의 영숫자 순서에 따라 정렬되어야 합니다
label_mode="int", # 'int': 레이블이 정수로 인코딩됨을 의미합니다
class_names=None, # "labels"가 "inferred"인 경우에만 유효
color_mode="rgb",
batch_size=32, # defualt 32
image_size=(256, 256), # defualt ( 256, 256 )
shuffle=True,
seed=None,
validation_split=None,
subset=None,
interpolation="bilinear",
follow_links=False,
crop_to_aspect_ratio=False,'Deep Learning, DL > Computer Vision' 카테고리의 다른 글
| CNN의 기본 과정 정리 (0) | 2022.01.08 |
|---|---|
| Generative Adversarial Networks, GAN (0) | 2021.08.29 |
| AutoEncoder, AE (0) | 2021.08.28 |
| Image Segmentation(FCN, U-Net) (0) | 2021.08.28 |
| Convolutional Neural Networks, CNN / window? (0) | 2021.08.28 |




댓글