- Image Segmentation 개념을 이해하고 대표 모델을 활용할 수 있다.
- Image Augmentation의 개념을 이해하고, 기본적인 증강방식을 활용할 수 있다.
- Object Recognition 개념을 이해하고, 활용할 수 있다.
정리 : https://github.com/codestates/AIB04_Discussion/discussions/26
Segmentation
Vision 연구가 발전된 방향을 보면, 처음에는 분류만 해보다가,
1. 입력 이미지에서 개체(Object)가 있는 위치를 찾을 수 있을까?
2. 해당 개체들을 의미적(semantic)으로 분류해볼 순 없을까?
3. 이미지 안에 한 개의 클래스만 있는 게 아니라 여러 종류의 클래스가 있다면,
각각의 픽셀들이 어느 클래스에 속하는 지 알 수 있을까?
Segmentation의 목적은
원본 이미지의 각 픽셀에 대해 클래스를 구분하고 인스턴스 및 배경을 분할하는 것 으로 위치 정보가 매우 중요
| Single object | Multi-objects | ||
| 분류 | 분류와 위치 | 객체 탐지(여러개) | 픽셀단위로 분류(Segmentation) |
| classification = FNN, MLP |
classification+ Localiztion = CNN |
Object Detectio (Recogntion) = R-CNN, YOLO |
*Instance Segmentation = U-Net *Semantic Segmentation = FCN |

* Instance Segmentation
- 각각의 사물들을 분류 => 같은 클래스라도 각각 분류한다( U-Net )
* Semantic Segmentation(의미론적)
- 똑같은 사물들을 각각 나눠서 분류하지 않고 하나의 묶음으로 본다( FCN )
= 이미지에 있는 모든 픽셀에 대한 예측
Segmentation은 각각의 물체가 어떤 class인지만 구분하는 Semantic Segmentation
같은 class일지라도 서로 다른 물체로 구분하는 Instance Segmentation으로 나뉜다.
* Semantic Segmentation은 이미지의 일부를 추출해 이 부분의 픽셀이 어떤 class에 속하는지를 분류
FCN(Fully Convolutional Network)
- Semantic Segmentation
예컨대 소의 머리 부분을 쪼개 해당 픽셀이 소인지 풀밭인지를 구분할 수 있다.
하지만 이처럼 이미지를 작은 영역으로 모두 쪼개 계산할 경우 연산량이 많아져 효율이 떨어진다.
이와 같은 문제를 해결하기 위한 기법이 Fully Convolutional Network이다.
Segmentation은 이미지를 단순히 '사람'이라고 분류하는 게 아니라, 이미지의 특정 영역을 라벨링하여
'자전거'를 타고 있는 '사람'처럼 표현하고자 하는 모델링이었다. 다시 말해 Classification은 이미지를
입력받아 이미지 하나에 대한 카테고리를 출력하지만, Segmentation은 이미지를 입력받아 이미지의
픽셀에 대한 카테고리를 출력한다.
https://m.blog.naver.com/9709193/221974662268
[딥러닝] 2-1. Fully Convolutional Networks(FCN)
◈ 혼자 공부하고 정리한 글로 부정확한 내용이 포함될 수 있음. ◈ 관련 서적, 온라인 강의, 블로그 등을 ...
blog.naver.com
* FCN의 단점
FCN 모델은 정해진 Receptive Field 를 사용해서 작은 물체들은 무시가 되거나 이상하게 인식 될 수 있고,
큰 물체를 작은 물체로 인식하거나 일정하지 않은 결과가 나올 수 있다.
또한, Pooling 을 거치면서 해상도가 줄어든 것을 Upsampling을 통해서 복원하는 방식을 사용해서,
결과가 정확하지 않다는 문제점을 가지고 있다.
일단 이런 모델은 parameter 의 개수와 차원을 줄이는 layer 를 가지고 있어서 자세한 위치정보를
잃게 되고, 또한 보통 마지막에 쓰이는 Fully Connected Layer에 의해서 위치에 대한 정보를 잃게 된다.
공간/위치에 대한 정보를 잃지 않기 위해서 Pooling 과 Fully Connected Layer 를 없애고
stride 가 1이고 Padding 도 일정한 Convolution 을 진행할 수도 있겠지만 input의 차원은 보존하겠지만,
parameter 의 개수가 많아져서 메모리 문제나 계산하는데 비용이 너무 많이든다.
== > Upsampling 시 더 좋은 성능을 내기 위한 방법으로 보완
Upsampling
딥러닝에서 convolution layer를 깊게 쌓을 수록 feature map의 크기가 계속 작아지게 되는데,
반대로 output의 크기가 input보다 커지게 하는 방법을 Upsampling 이라고 한다
Interpolation 이란?
Interpolation(인터폴레이션, 보간)이란 알려진 지점의 값 사이(중간)에 위치한 값을 알려진 값으로부터
추정하는 것을 말한다. Interpolation과 대비되는 용어로 extrapolation이 있는데,
extrapolation은 알려진 값들 사이의 값이 아닌 범위를 벗어난 외부의 위치에서의 값을 추정하는 것을 말한다.
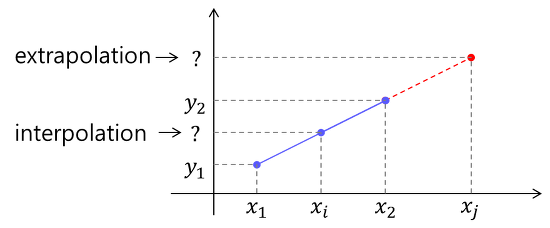
예를 들어
어떤 사람이 20살일때 키와 40살에서의 키를 보고 30살에서의 키를 추측하는 것은 interpolation
과거 1살때부터 현재 나이까지의 키를 보고 앞으로 10년 후의 키를 예측하는 것은 extrapolation
Linear Interpolation 선형보간법
- 두 지점 사이의 값을 추정할 때 그 값을 두 지점과의 직선 거리에 따라 선형적으로 결정하는 방법
Bilinear Interpolation 쌍선형 보간법, 또는 이중선형 보간법
- 1차원에서의 선형 보간법을 2차원으로 확장한 것
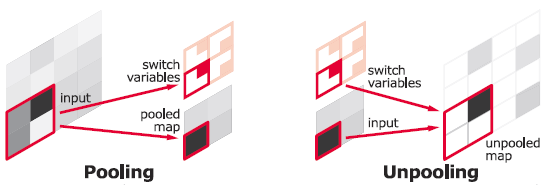
Unpooling
- 말그대로 Pooling을 역으로 수행한다. Pooling할 때의 index를 기록해 두었다가
해당 index를 기반으로 거꾸로 Pooling을 한다.
Transposed Convolution(= Upconvolution / Deconvolution)
- Deconvolution하고 차이가 있는듯?
- 상황을 악화시키기 위해 deconvolution이 존재(= 연산 값이 달라서? 행렬곱은 순서가 중요)
Transposed convolution을 up-sampling시 사용할 수 있습니다. 또한
Transposed convolution의 가중치들은 학습 가능하기 때문에 미리 정의된 보간 방법이 필요하지 않습니다
Convolution 계산을 하면 feature map이 작아진다.
반대로 feature map이 커지게 하려면 어떻게 해야할까?
transposed Convolutional layer는 반대로 주로 upsamping을 실행합니다. 즉 input 보다 output의
공간적 차원이 더 큽니다. 일반적인 convolutional과 동일하게 역시 padding과 stride를 통해서
정의할 수 있습니다. 이런 padding과 stride값들은 이론적으로 output에 대하여 input을 만들어내기
위한 값입니다. 예를 들어 output에다가 stride와 padding의 값을 가지고 일반적인 Convoltuion을 한다면,
input과 동일한 공간적 차원을 만들어낼 것입니다.
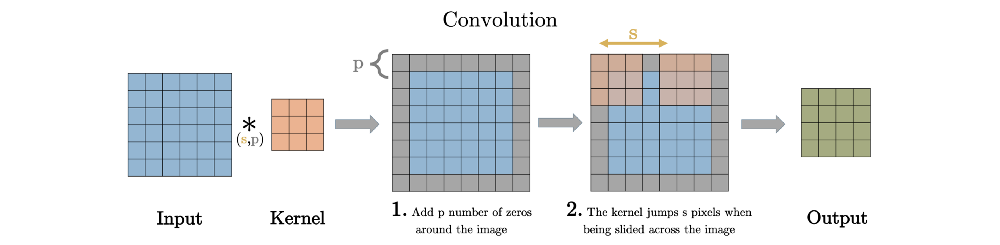
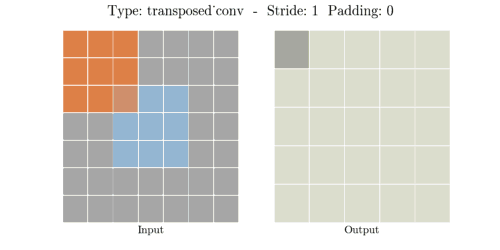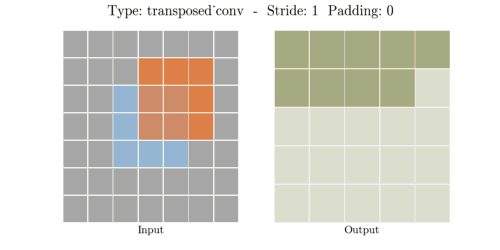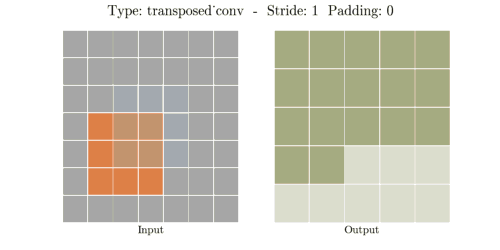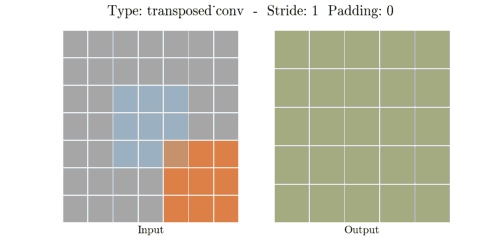
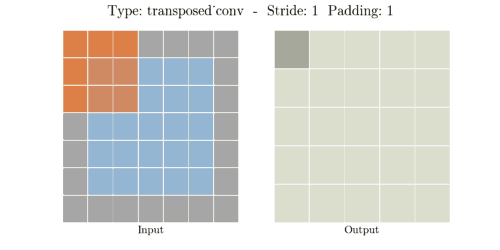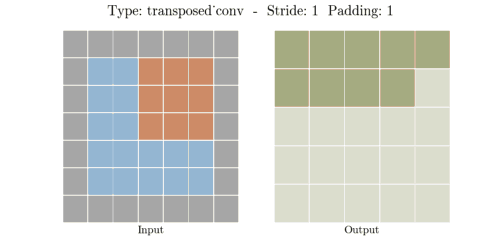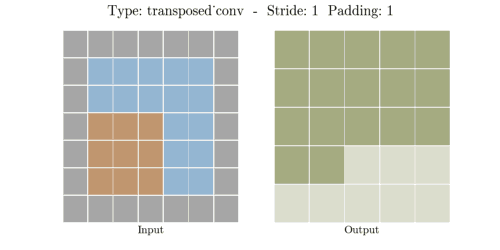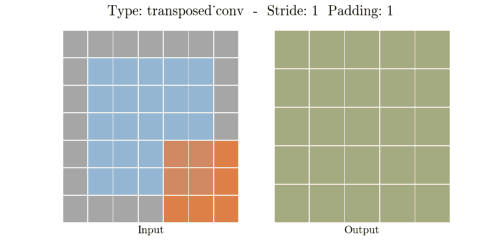

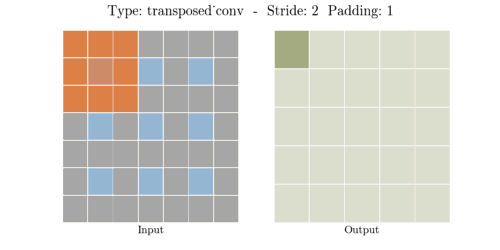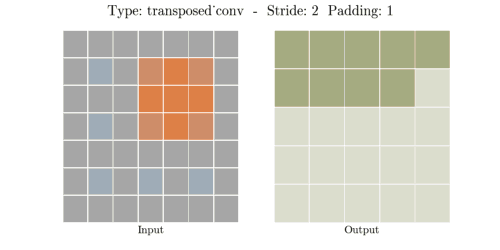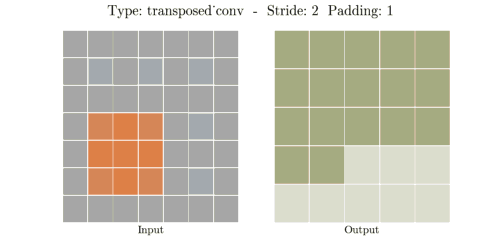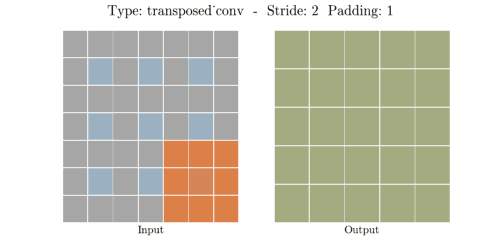
stride는 convolution 연산할 때 input에서 sliding window가 움직이는 보폭을 의미한다.
Transposed Convolution은 Convolution을 거꾸로 하는 개념이라고 했다. stride 2를 거꾸로 생각하면
stride 1/2이 된다. stride가 1/2이라는 말은 2번 움직여야 다음 원소에 도달한다는 말과 같다.
위 이미지에서 input(파란색)의 한 원소에서 다음 원소까지 도달하는데 sliding이 2번 필요하다.
원소간에 공백 때문에 1/2씩 움직이는 개념이 된다.
Skip Connection 원리
Coarse한 feature map을 Dense하게 만들어 주는 Upsampling은 사실 높은 성능을 기대하기 어렵다.
이미 작아진 feature map은 디테일이 많이 사라진 상황이기 때문에 다시 크기를 키워도 정교한
예측이 어렵기 때문이다. 실제로 아래 이미지의 stride 32는feature map의 정보 하나를 32개로 늘려
32배로 부풀린 결과인데 디테일이 많이 부족한 것을 확인할 수 있다. 1/32만큼 줄어든 이미지를
한 번에 32배만큼 Upsampling했기 때문에 어떻게 보면 이미지가 뭉개지는 것은 당연하다. 따라서
이와 같은 문제를 해결하기 위해 skip layer를 활용해 성능을 높이고자 한다.
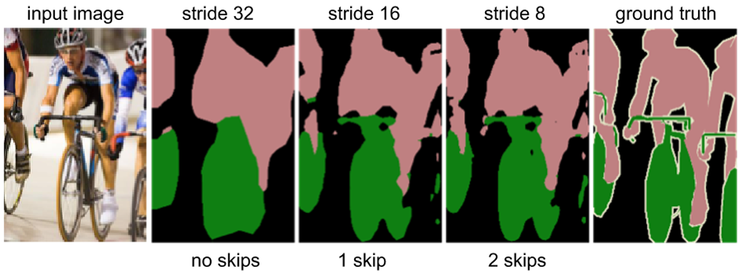
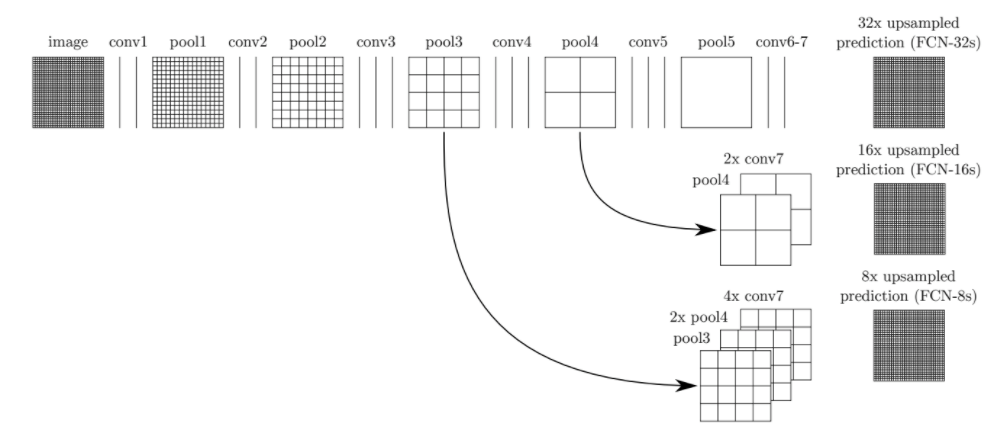
FCN-32s는 7번째 Convolutional Layer를 거친 feature map을 stride 32로 Upsampling한 결과이다.
하지만 위에서 이미 확인했다시피 이는 훌륭한 복원 결과가 아니다. 따라서 생각해 낸 방법은 1/32배로
줄어든 이미지 뿐만 아니라 1/16배, 더 나아가 1/8배로 줄어든 이미지를 함께 사용하자는 것이다.
즉, 조금 더 디테일한 이전 Layer의 정보를 가져와복원하는 원리이다.
먼저 FCN-16s는 어떤 과정을 거쳐 나왔을까?
1) 5번째 Pooling Layer를 stride 2로 Upsampling한 결과(2× conv7)를
2) 4번째 Pooling Layer의 결과(pool4)와 합쳐준 뒤, 이를 stride 16으로 Upsampling한다.
pool4의 conv5와 pool5 단계를 건너뛰고 결과를 합쳤으므로 skip을 1번한 셈이다.
비슷한 방식으로 FCN-8s는 2번의 skip을 거쳐 완성된다
U-Net
- Instance Segmentation
Semantic Segmentation은 같은 라벨의 객체(instance)를 구분하지 않기 때문에 이미지 속 사람이 3명이어도
3명의 사람을 구분해서 표시할 수 없다는 단점이 있었다.
이 모델로는 그저 '사람'이라는 라벨링된 픽셀을 얻을 뿐이다
"U-Net의 아이디어는 다음과 같다.
1) sliding window가 아닌 patch 탐색 방식을 사용한다(속도 향상).
2) Contracting Path에서는 이미지의 context를 포착한다.(= context는 서로 이웃한 이미지 픽셀 간의 관계를 의미)
그리고 Expanding Path에서는 feature map을 Upsampling한 뒤, 이를 Contracting Path에서
포착한 (feature map의)context와 결합하여 localization의 정확도를 높인다(trade-off 해결)."
trade-off라 함은 넓은 범위의 이미지를 한꺼번에 인식하면 전반적인 context를 파악하기에 용이하지만
localization를 제대로 수행하지 못해 어떤 픽셀이 어떤 레이블인지 세밀하게 인식하지 못한다.
반대로 범위를 좁히면 세밀한 localization이 가능하지만 context 인식률은 떨어진다
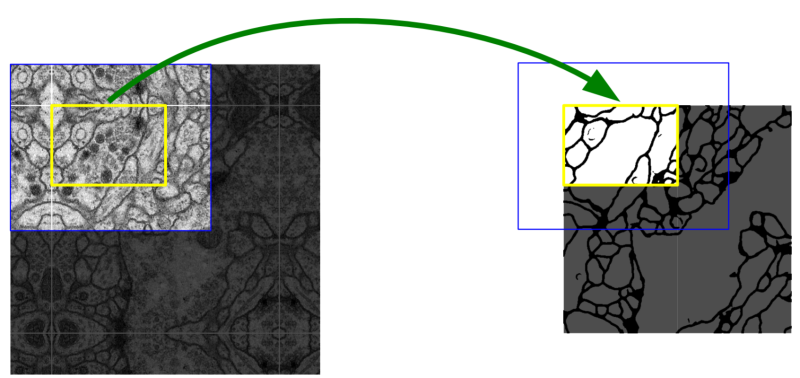
Patch(=Tile)??
이미지 인식 단위를 의미한다. 기존의 sliding window 방식과 patch 방식의 차이는 아래 그림에서 명확히 나타난다.

sliding window 방식에서는 이미 사용한 영역의 일부를 다음 순서에서도 다시 훑어보기 때문에 중첩되는
부분이 생긴다. 이는 이미지를 잘게 쪼개 같은 작업을 조금씩 반복하는 것으로 속도 향상에 있어 별 도움이
되지 않는다. 반면, patch 탐색 방식은 이미지를 격자 모양으로 잘랐기 때문에 중첩되는 부분이 존재하지 않는다.
이미 훑어본 영역은 깔끔하게 넘기고 다음 patch부터 탐색을 시작하므로 속도 면에 있어 훨씬 나은 성능을 보인다.
즉, U-Net은 patch 탐색을 통해 이미 검증한 부분은 건너뛰어 속도를 높인다.
FCN과 비교해 달라진 점은 무엇일까?
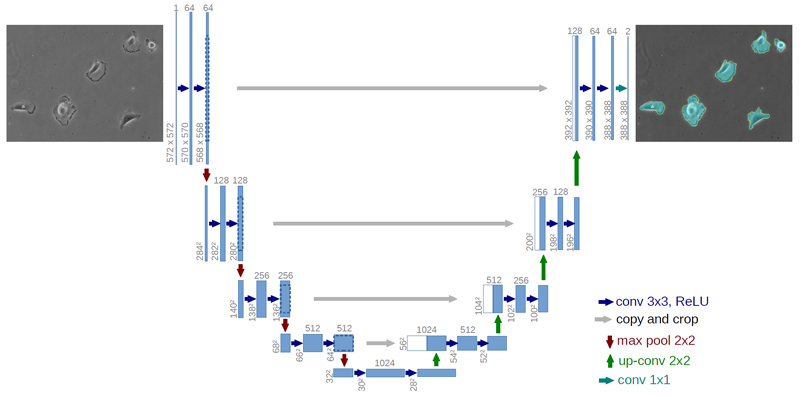
첫째, Decoding 영역의 Pooling Layer(빨간색 화살표)가 사라지고 Upsampling(초록색 화살표)으로 대체되었다.
둘째, 각 Encoding 영역과 Decoding 영역이 서로 수평관계(회색 화살표)에 있다.
그리고 Decoding 영역의 각 파란색 feature map 좌측에 하얀색 feature map이 추가되어 Encoding 영역의
feature map과 대응된다.
이는 Encoding 영역에서 출력된 결과물의 일부를 복사해 Decoding영역과 결합함을 의미한다.
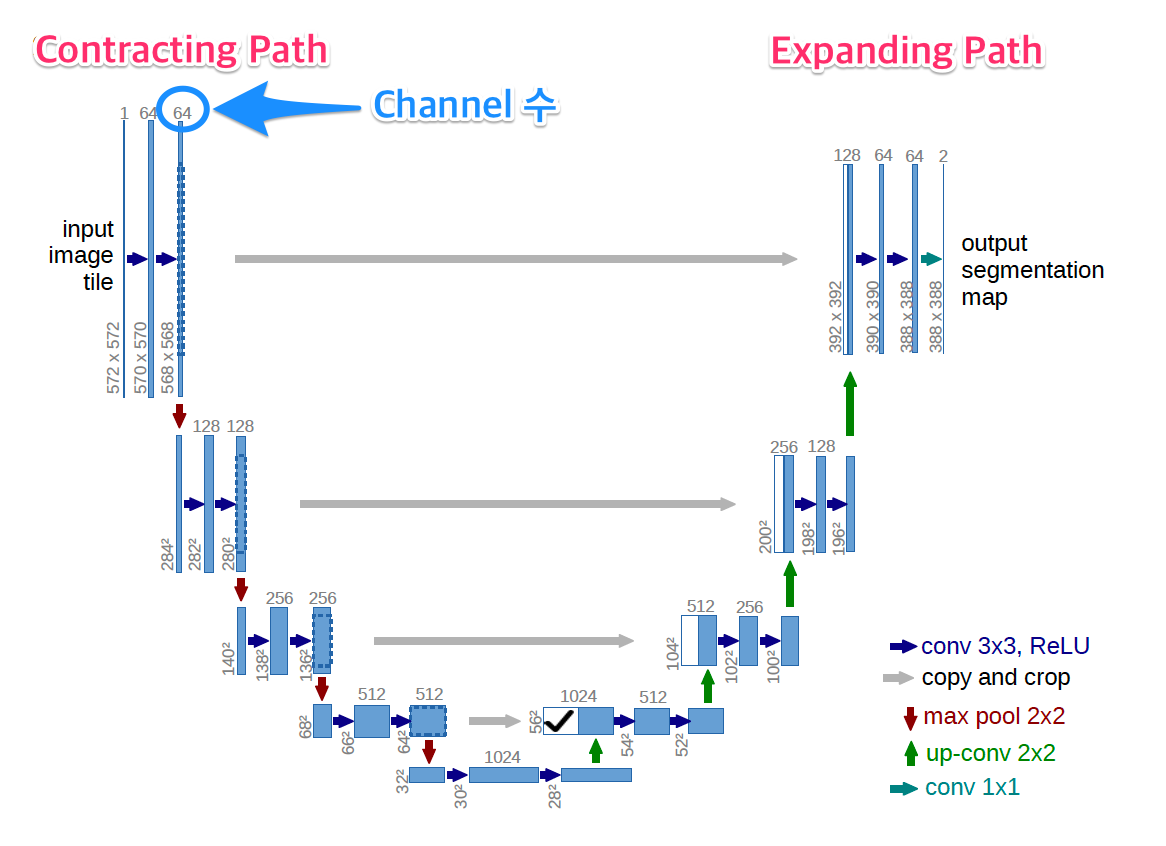
Architecture Detail
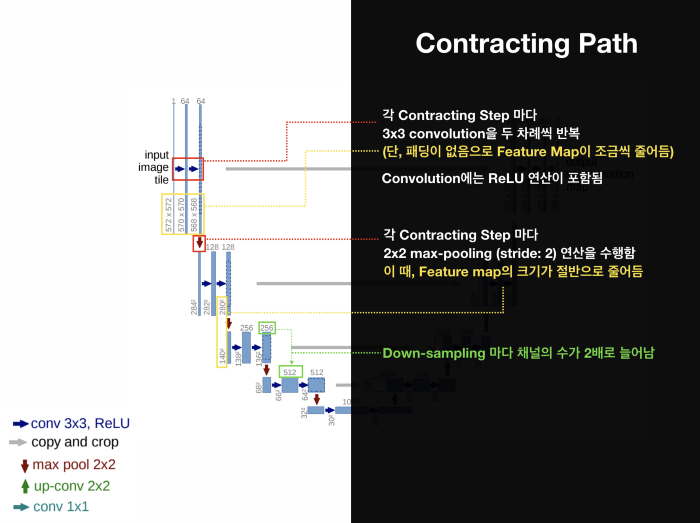
1. Contracting Path
- Input 이미지의 context를 포착하는 단계
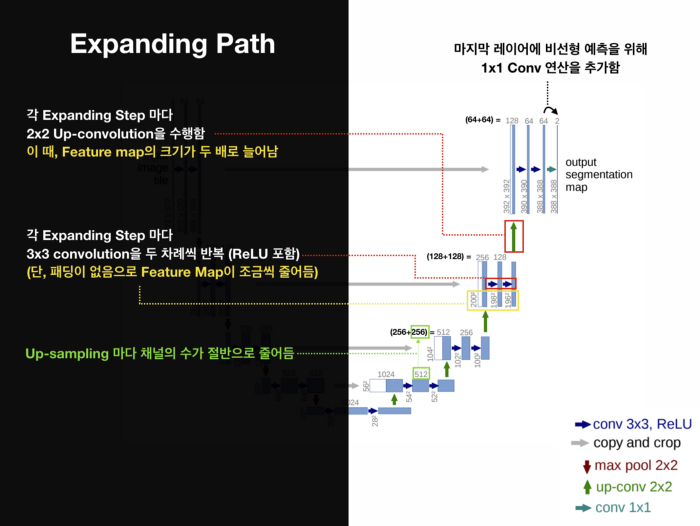
2. Expanding Path
- 정확한 localization을 위한 단계이다. Contracting Path를 거친 feature map은 Downsampling으로 해상도가 많이 떨어져 있다. 해상도를 높이기 위해 Upsampling을 여러 차례 진행한다. FCN과 마찬가지로 Coarse Map을 Dense Map으로 바꾸기 위함이다.
상단 그림에서 확일할 수 있다시피 Input 사이즈는 572×572지만, Output 사이즈는 388×388이다. 이는 padding
없이 Convolution 연산을 수행했기 때문이며 단순히 크기가 작은 게 아니라 외곽이 잘려나간 형태가 된다
이 같은 missing data 문제를 해결하기 위해 사용한 것이 mirroring padding이다.
* Overlap-tile / Mirror padding / Mirror Extrapolation

원래대로라면 노란색 영역 바깥 부분은 Convolution에 의해 사라지지만 이렇게 인접한 부분을
mirroring해 확장시키면 missing data를 채울 수 있다.
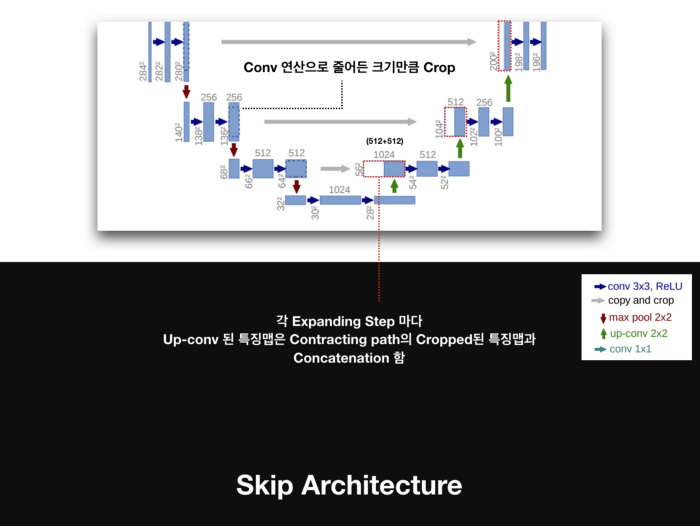
3. Skip connection
Contracting Path에서 Pooling 직전 단계의 feature map을 복사해 Expanding Path에서 대응되는 feature map에 concat 시킨다. 주의할 점은 앞서 설명했듯이 missing data가 발생하기 때문에 Contracting Path의 feature map에 비해 Expanding Path의 feature map의 크기가 더 작다는 것이다.
그래서 이미지 보정을 위해 가운데 부분을 알맞은 사이즈로 Crop을 해서 조금 작은 이미지로 재조정한 뒤에 가져와 붙인다. Expanding Path에서는 Upsampling 단계를 거친 뒤 이 같은 Copy&Crop&Concat (Paste) 과정을 매 단계마다 반복해서 수행한다. 이에 따라 2장의 feature map이 겹쳐진 상태로 다음 단계인 Convolution을 거친다.
이 과정에서 feature들이 서로 융합되며, 결과적으로 같은 위치(픽셀)에 있는 값들이 더욱 잘 라벨링된다.
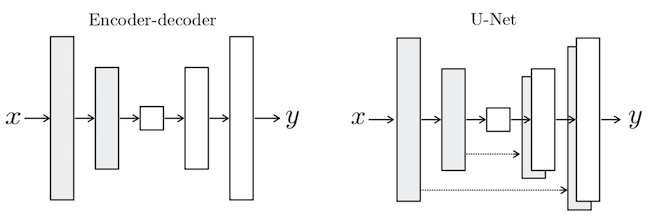
영상 크기를 줄였다가(subsampling) 다시 키우면(upsampling) 정교한 픽셀 정보가 사라지게 됩니다.
이는 픽셀 단위로 조밀한 예측이 필요한 이미지 분할에선 큰 문제가 되죠.
이에 인코더에서 디코더로 중요 정보를 직접 넘겨주는 스킵커넥션을 통해 디코더 부분에서 훨씬 더
선명한 이미지를 결과를 얻게 됨에 따라 더 정확한 예측이 가능합니다.
보통 연구에서 UNet을 활용했다고 한다면, 기본 구조(인코더, 디코더, 스킵커넥션)는 유지하되,
인코더나 디코더의 구성 방식이나 그 학습 방식을 조정했다고 보시면 됩니다.
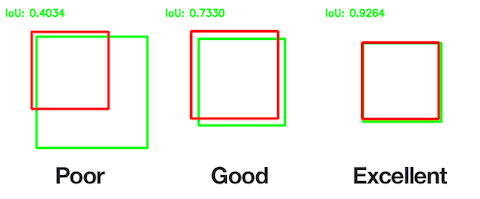
# 모델 성능 평가 IOU(intersection over union)
일반적으로 잘 알려진 IOU(intersection over union)방식 아래 [그림 6]에서 보는 것처럼 예측 마스크 영역과 실제 마스크 영역이 서로 얼마나 겹치느냐를 측정하기 때문이죠. 겹치는 영역이 1에 가까울수록 성능이 좋고(excellent), 0에 가까울수록 성능이 좋지 않다고 측정합니다(poor).
* skipped connection
- bottle neck으로 디테일이 많이없어지기 때문에 사용
!pip install -U segmentation-models
# U-Net + ResNet50
from segmentation_models import Unet, Linknet, PSPNet, FPN
import segmentation_models as sm
n_classes = 3
activation = 'softmax'
# create model
model = sm.Unet('resnet50', classes=n_classes, activation=activation, encoder_weights=None, encoder_freeze=True)
# iou score, f1 score
metrics = [sm.metrics.IOUScore(threshold=0.5), sm.metrics.FScore(threshold=0.5)]
model.compile(loss = 'categorical_crossentropy',
optimizer=Adam(learning_rate=0.001),
metrics= 'acc'
)Computer Vision의 4가지 과제
1. Classification? input에 대해서 하나의 레이블을 예측하는 작업
2. Object Detection? 물체의 레이블을 예측하면서 그 물체가 어디에 있는지 정보를 제공
3. Image Segmentation? 모든 픽셀의 레이블을 예측
4. Visual relationship?
'인공신경망(DL) > Computer Vision' 카테고리의 다른 글
| CNN의 기본 과정 정리 (0) | 2022.01.08 |
|---|---|
| 전이학습 (Transfer Learning), 데이터 증강(Augmentation) (0) | 2022.01.08 |
| Generative Adversarial Networks, GAN (0) | 2021.08.29 |
| AutoEncoder, AE (0) | 2021.08.28 |
| Convolutional Neural Networks, CNN / window? (0) | 2021.08.28 |




댓글