- Part 1: Convolution & pooling 개념을 설명할 수 있다.
- Part 2: CNN을 이용하여 분류(Classification)문제에 적용할 수 있다.
- Part 3: 전이학습(transfer learning)을 이용하여 image classification을 할 수 있다.
정리 : https://github.com/codestates/AIB04_Discussion/discussions/24
최근의 컴퓨터비전(Computer vision, CV)는 대부분을 convolution에 의존하고 있다고해도 과언이 아니다.
Weights를 공유하며, 특징을 추출하는데 이만한 방법론을 찾기 어렵기 때문이다.
- 사물인식 - Object Detection (YOLO) + RCNN(Fast, Faster, MASK RCNN)
- 포즈예측 - Pose Estimation (PoseNet)
- 윤곽분류 - Instance Segmentation (Detectron)
- Etc... 셀수 없이 많은 다양한 사례들...
| Single object | Multi-objects | ||
| 분류 | 분류와 위치 | 객체 탐지(여러개) | 픽셀단위로 분류 |
| classification = FNN, MLP |
classification+ Localiztion |
Object Detectio (Recogntion) = R-CNN, YOLO |
*Instance Segmetation = U-Net *Semantic Segmentation = FCN |
CNN
여러개의 filter로 Conv연산을 통해 파악한 특징을 추출하는 것이 Conv layer의 역할
Dimension of Image Data = ( samples, height, width, channel )
height, width = 행렬관점에서 Row, Column
- 고양이의 시각피질의 수용영역(receptive field)에서 영감을 받았다.
* 시각피질이란?
- 뉴런은 특정영역, 모양, 색상, 방향 ... 일반적인 시각적 특징을 수용하도록 영역별로 전문화가 이루어진다.
즉, 시야 내의 특정영역에 대한 자극만 수용한다는 것이다.
* 고려해야할 것
크기, 각도, 밝기, 위치 ...
* imange ( H, W, C ) ==> 3차원 Tensor / 각 픽셀 = 0 ~ 255 값을 가지고 있다.
= 높이 너비 채널
= 세로 가로 색의 성분(= depth)
( 통상적으로 접하게 되는 color는 R G B = channel 수 3
*왜 이미지 분류할때는 CNN을 쓸까?*
- 이미지 데이터의 특징은 인접 픽셀들 간의 유사도가 매우 높다
==> 픽셀 수준이 아니라 특정 속성을 갖는 국소영역 수준으로 표현이 가능하다.

* FNN을 사용하게 되면 ( Dense() ) FC
* 인접 픽셀간의 상관관계가 무시된다
1. flatten시켜서 한줄 데이터로 만들게 되는데 이 과정에서
이미지의 공간적/지역적 정보(spatial/topological information)가 손실
FNN을 사용하게되면 이미지 행렬을 한 줄로 쭉 펴는 작업인 Flatten이 필요
이렇게 되면 이미지에서는 분명히 붙어 있는 픽셀인데 Flatten한 행렬에서는 서로 떨어지게됨
== 이미지의 공간적인 구조(Spatial structure) 무시된다
2. 학습시간과 능률의 효율성이 저하( 많은 parameter로 인해 )
고해상도의 이미지일 경우
ex) 1000*1000*3 == 무수히 많은 param가 존재
단순히 fully connected 방식으로 진행하기에는 너무 많은 연산이 필요
= 컴퓨터 리소스 많이차지
input pixel 수는 1000*1000*3 + bias
예를들어 첫번째 layer가 1000개의 노드를 가지고 있다하면 (1000, 3milion)이됨
결국 첫번째 layer weight는 1000*3milion이 되는... 30억?
* CNN을 사용하게 되면
일단 구조적 유사성을 배우도록 훈련을 하게 된다.
(이미지 전체보다는 부분을 보는 것, 그리고 이미지의 한 픽셀과 주변 픽셀들의 연관성을 살리는 것 )
Convolutional layer는 Conv연산을 사용 = filter를 slide함으로써 주위 픽셀들을 계산
== 이미지의 공간적인 구조를 보존할 수 있다.
1. 이미지 형태를 보존하도록 행렬 형태의 데이터를 입력 받고
2. 단순히 filter들을 모수화 할 수 있을 정도의 model parameter만 필요로 한다.
CNN의 마지막 fully-connected는 원본이미지가 아닌 Pooling을 통해 축소된 이미지를
처리하는데 이로 인해 가중치 또한 줄어든다.
== 점점 더 작은 피쳐맵으로
* 이전 이미지 학습 기술에 비해 이미지 전처리 (자르기 / 센터링, 정규화 등)가 상대적으로
거의 필요하지 않습니다.
* 이와 관련하여 이미지의 모든 종류의 일반적인 문제 (이동, 조명 등)에 대해 견고 함
CNN은 Convolution(합성곱)을 적용하여 시각적 접근 방식을 모방
( 합성곱층은 합성곱 연산을 통해서 이미지의 특징을 추출하는 역할 )
합성곱에서 다수의 kernel을 사용할 경우 사용한 kernel 수는
= 합성곱 연산의 결과로 나오는 Feature map 채널(channel) 수
합성곱으로 얻은 Feature map의 채널차원은 RGB채널과 같은 컬러의 의미를 갖고 있지 않다.
=커널(kernel) 또는 필터(filter)라는 n×m 크기의 행렬로 ( 보통 3 x 3 or 5 x 5 사용 )
높이(height)×너비(width) 크기의 이미지를 처음부터 끝까지 겹치며 훑으면서 n×m크기의 겹쳐지는
부분의 각 이미지와 커널의 원소의 값을 곱해서 모두 더한 값을 출력으로 하는 것
합성곱으로 만들어 진것이 Feature map이라고 부른다 == Stride를 수정해서 Kernel의 이동 범위 조정 가능
*커널(kernel), 필터(filter)
- 가중치의 집합, 합성곱을 하면 이 행렬로 인해 크기가 작아진다.(= 차원수가 줄어든다)
= 가중치 (weights parameters)의 집합으로 이루어져 가장 작은 특징을 잡아내는 창

입력 이미지는
채널 수가 1,
너비가 3 픽셀, 높이가 3 픽셀이고,
크기가 2 x 2인 필터가 하나인 경우를 레이어로 표시
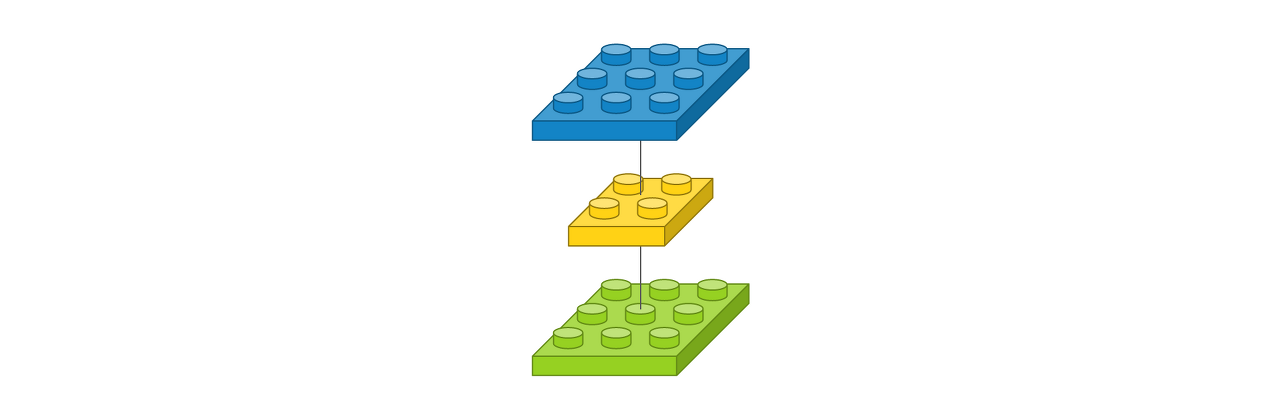
# 그림1
Conv2D(1, (2, 2), padding='same', input_shape=(3, 3, 1))
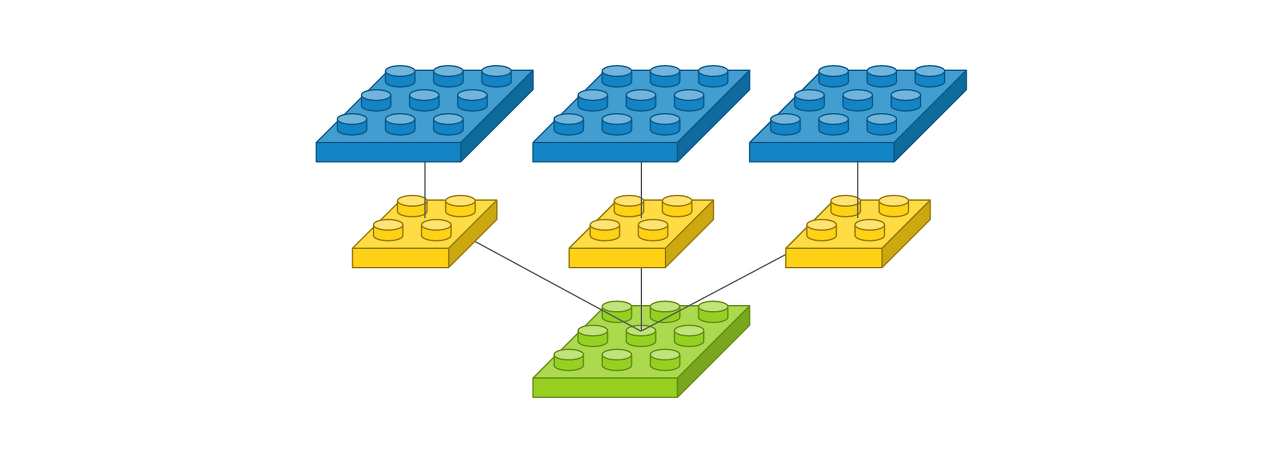
# 그림2
Conv2D(3, (2, 2), padding='same', input_shape=(3, 3, 1))필터가 3개라서 출력 이미지도 필터 수에 따라 3개로 늘어난다.
총 가중치의 수는 3 x 2 x 2 x 1으로 12개(= filter * kernel size * channel)
* 주의 *
필터마다 고유한 특징을 뽑아 고유한 출력 이미지로 만들기 때문에 필터의 출력값을 더해서
하나의 이미지로 만들거나 그렇게 하지 않는다.
== 적용되는 필터 수에 따라 다른 사진이 나온다(스마트폰 카메라 필터)
출력 이미지 사이즈가 3 x 3이고 총 3개 = 이는 채널이 3개다라고도 표현

# 그림3
Conv2D(1, (2, 2), padding='same', input_shape=(3, 3, 3))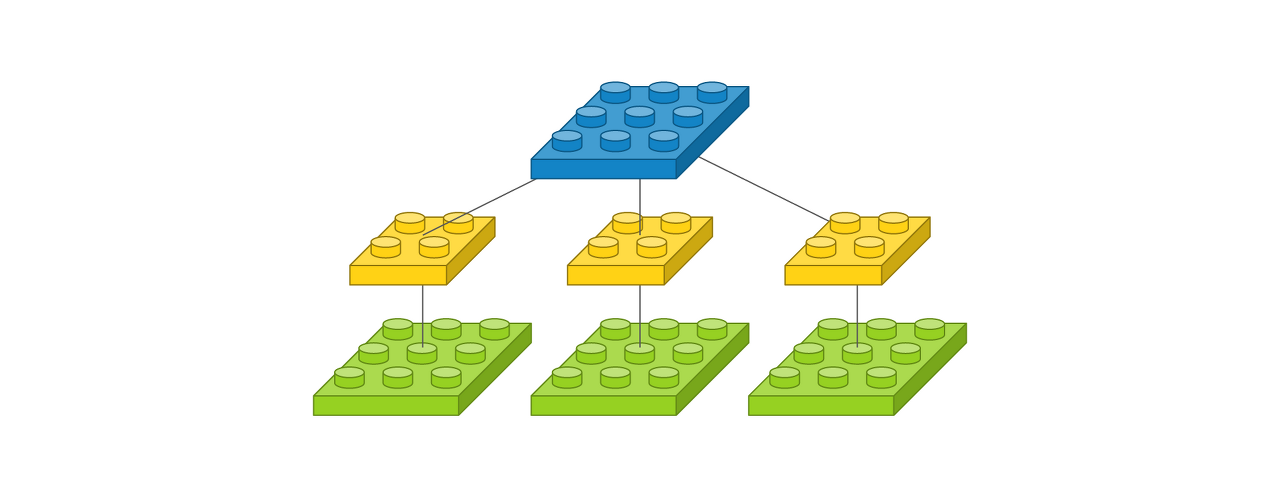

필터 개수가 3개인 것처럼 보이지만 이는 입력 이미지에 따라 할당되는 커널이고,
각 커널의 계산 값이 결국 더해져서 출력 이미지 한 장을 만들어내므로 필터 개수는 1개
가중치는 1 x 2 x 2 x 3으로 총 12개(= filter * kernel size * channel)
출력 이미지는 사이즈가 3 x 3 이고 채널이 1개
# 그림4
Conv2D(2, (2, 2), padding='same', input_shape=(3, 3, 3))

2 x 2 커널을 가진 필터가 2개, 채널마다 커널이 할당되어 총 가중치는 2 x 2 x 2 x 3로 24개
출력 이미지는 사이즈가 3 x 3 이고 채널이 2개
*특성맵(Feature map)
- 합성곱으로 만들어진 것
*Stride
- 이동 폭을 말한다.
=이동 폭이 큰 만큼 다음 레이어의 데이터의 수가 줄어든다.
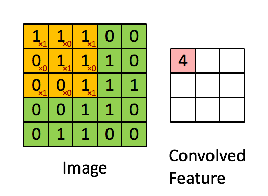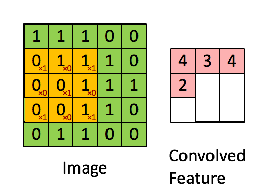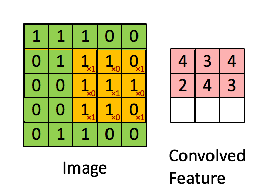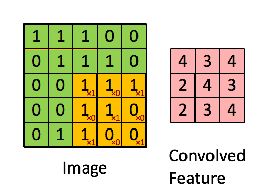
Stride 계산
입력 크기 (H, W)
필터 크기 (FH, FW)
출력 크기 (OH, OW)
패딩 ( P )
스트라이드( S )

- 입력 데이터 Shape = (39, 31, 1) # (h, w, dim)
- 입력 채널=1
- 필터=(4, 4)
- 출력 채널=20
- Stride = 1
입력 채널: 1
출력 데이터(Activation Map) Shape: (36, 28, 20)
학습 파라미터: 320개 (1 X 4 X 4 X 20)
*Padding

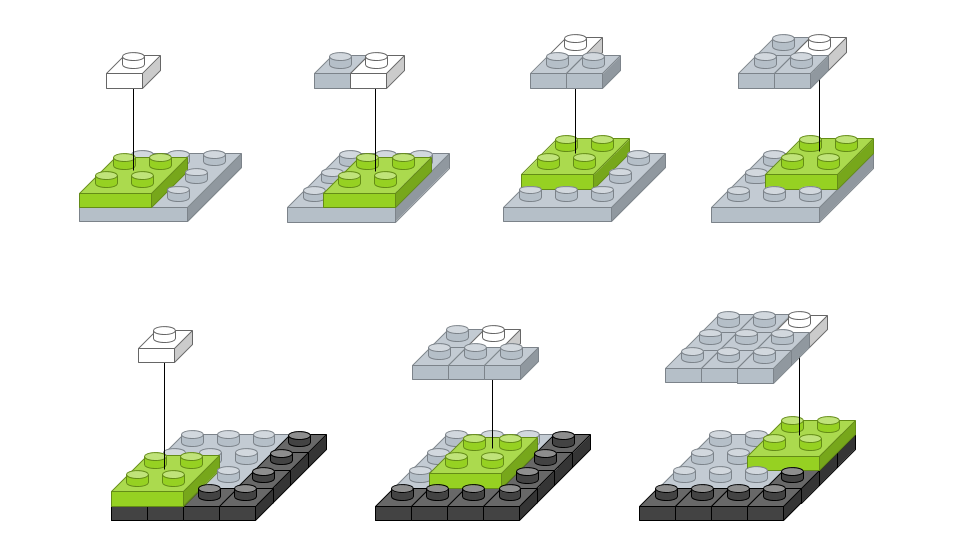
padding 흰 색 pixel의 경우는 실제 이미지가 있는 부분이고, 짙은 회색의 pixel은 feature map의 크기
조절과 데이터를 충분히 활용하기 위해 가장자리에 '0'을 더해준 것,이런 방식을 zero-padding
ex) 6x6 행렬에 Padding을 한번해서 8x8행렬로 만든 후 fiter적용 = 원본이미지 6x6행렬이 된다
==> 가장자리 픽셀에 대한 연산을 온전히 해줄 수 있다.
‘valid’인 경우에는 입력 이미지 영역에 맞게 필터를 적용하기 때문에 출력 이미지 크기가
입력 이미지 크기보다 작아집니다.
‘same’은 출력 이미지와 입력 이미지 사이즈가 동일하도록 입력 이미지 경계에 빈
영역을 추가하여 필터를 적용합니다.
왜 Padding 쓸까?
만일 convolution 층을 여러개 쌓았다면 최종적으로 얻은 특성맵(Feature map)은 초기 입력보다
매우 작아진 상태가 된다. ==> 손실되는 부분이 발생한다는 뜻
1. 합성곱 이후에도 입력의 크기와 동일하게 유지하고 싶다면??
Padding을 사용한다 (합성곱 연산을 하기 전에)
2. 또한, Edge 쪽 픽셀 정보를 더 잘 이용하기위해 사용
* Pooling
- Feature map을 다운 샘플링 = Output dimension이 작아지며 Parameter수를 줄인다
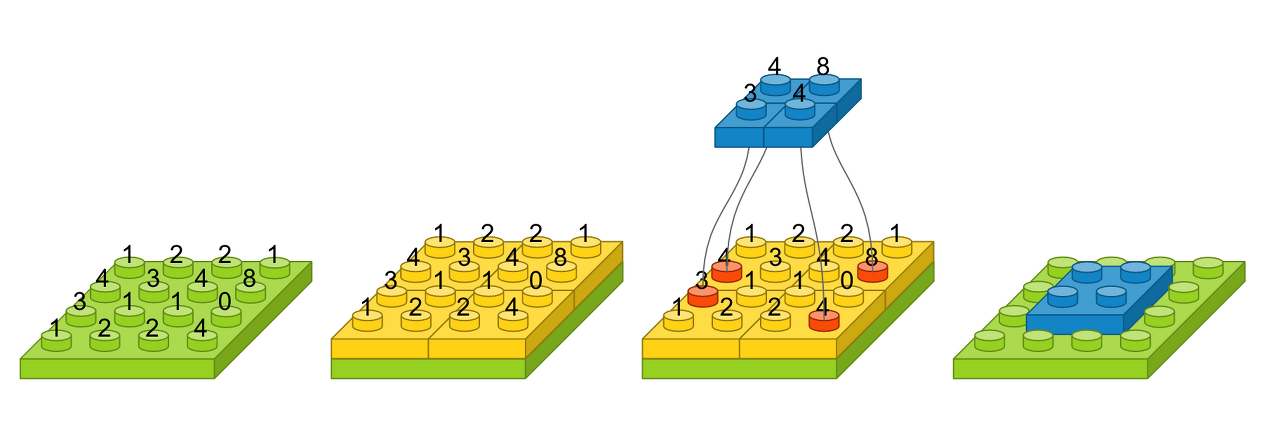
해당 풀에서 가장 큰 값을 선택하여 파란 블럭으로 만들면, 그것이 출력 영상
얼굴 인식 문제를 예를 들면, 맥스풀링의 역할은 사람마다 눈, 코, 입 위치가 조금씩 다른데 이러한
차이가 사람이라고 인식하는 데 있어서는 큰 영향을 미치지 않게한다.
왜 Pooling 쓸까?
Conv 연산 이후 나온 모든 특징을 사용할 필요는 없기 때문에 pooling을 통해
Feature map 크기를 축소 = 다음 단계에 사용될 메모리 크기와 계산이 감소한다.
즉, 이미지 대표값만 추출하고자함 = 학습 파라미터가 없다.
ex) 고화질 사진을 보고 물체를 확인할 수 있지만 작은 사진을 가지고도 어떤 사진인지 판단 할 수 있다.
*주의*
합성곱과 유사하지만 함수를 사용하지 않는다
(= 학습할 가중치가 없고, 연산 후 채널 수는 변하지 않아)
대표적으로 두가지 방법으로 Max pooling과 Average pooling
*Max pooling = 특정 대표적인 값만 추출하겠다.
입력 채널: 1
출력 데이터(Activation Map) Shape: (36, 28, 20)
학습 파라미터: 320개 (1 X 4 X 4 X 20)
Max Pooling 크기가 (2, 2)
OH = 18 ( 36 / 2 )
OW = 14 ( 28 / 2 )
- 입력 채널: 20
- 출력 데이터 Shape: (18, 14, 20)
- 학습 파라미터: 0 Max Pooling Layer에서 학습 파라미터가 없다.
*Average pooling = 특정값이 아닌 주변값들도 다가져오겠다?( 이미지가 흐리게 나온다 )
== smoothing(일반화 성능을 올려준다)
- 해당 값(정답에 대해서는 1을 주고) 틀린 것에도 어느정도 값을 부여(0이 아닌)
1. Conv 연산
- 해당 사진과 filter 합성곱으로 특정한 특징이 있는지 없는지 검출
( 비선형 함수인 ReLU 사용 )
2. Pooling
- Conv연산으로 통해 나온 Feature map 크기를 줄인다.
.. 반복
3. Fully-connected ( Flatten 1D )
- 특성맵들을 일렬로 이어붙여서 F.C로 최종 클래스 분류한다.
( softmax함수 사용 )
왜 Flatten? 분류하기 위해( so, softmax사용 )
CNN에서 컨볼루션 레이어나 맥스풀링 레이어를 반복적으로 거치면 주요 특징만 추출되고,
추출된 주요 특징은 전결합층에 전달되어 학습
두번째 pooling layer에서 얻어낸 크기의 이미지들은 이미지 자체라기 보다는 입력된 이미지에서
얻어온 특이점 데이터가 된다.
= 즉 1차원의 벡터 데이터로 변형시켜주어도 무관한 상태가 된다는 의미
* 깊은 Convolutional 레이어일수록 더 큰 형태의 특징들을 뽑아낸다 *
from tensorflow.keras import datasets
from tensorflow.keras.models import Sequential, Model # <- May Use
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
# class 설정
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# 해당 class 시각화
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()train_images[0].shape
# (32, 32, 3)
# parameter 32*32*3
model = Sequential()
'''
Conv2D( filters개수 , Kernel, ... )
'''
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D((2,2)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D((2,2)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.summary()
# 모델학습방식을 정의함
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])

Output Shape=
stride 계산 식
conv2d =
kernel(3,3) * channel(3) * filter(32) + bias(32)
conv2d_1=
kernel(3,3) * channel(32) * filter(64) + bias(32)
conv2d_2=
kernel(3,3) * channel(64) * filter(64) + bias(64)
Dense=
shape(4*4*64) * node(64) + bias(64)
Dense= node(64)* node(10) + bias(10)

https://tykimos.github.io/2017/01/27/CNN_Layer_Talk/
컨볼루션 신경망 레이어 이야기
이번 강좌에서는 컨볼루션 신경망 모델에서 주로 사용되는 컨볼루션(Convolution) 레이어, 맥스풀링(Max Pooling) 레이어, 플래튼(Flatten) 레이어에 대해서 알아보겠습니다. 각 레이어별로 레이어 구성
tykimos.github.io
* Window란?
- 자연어처리에서 중심단어를 예측하기 위해 앞 뒤로 몇개의 단어를 볼 지를 결정했다면
이 범위가 " Window "
= 이 윈도우를 계속움직여서 주변단어와 중심단어를 바꿔가며 학습을 위한 data set을 만드는데
이것을 " sliding window " 라고 한다.
입력이미지를 작은단위로 쪼개고 (부위를 나눔)
ex) 머리 부분을 세부분으로== 머리부분 이외의 class가 많다면 머리class가 아닌 것으로 분류
이 단위 부분이 어떤 분류에 속하는지 classification을 하는 것
근데 모든 영역을 이렇게 한다는 건 비용이 많이든다. 만약 서로 다른 영역이라도 인접해 있다면
그 특징들을 공유를 할 수 있기 때문에 좋지 않다
==> 합성곱이 이러한 방식으로 연산을 하는데 엄청 큰 이미지 같은 경우에는 너무 느리기 때문에
" Selective Seach "를 사용한다.
'Deep Learning, DL > Computer Vision' 카테고리의 다른 글
| CNN의 기본 과정 정리 (0) | 2022.01.08 |
|---|---|
| 전이학습 (Transfer Learning), 데이터 증강(Augmentation) (0) | 2022.01.08 |
| Generative Adversarial Networks, GAN (0) | 2021.08.29 |
| AutoEncoder, AE (0) | 2021.08.28 |
| Image Segmentation(FCN, U-Net) (0) | 2021.08.28 |




댓글